I do a lot of experiments and I commonly need to create a very specific load on one of my test servers. (This is why I created a simple synthetic load generator tool.) But when I installed 11gR1 over a year ago the top wait event db file scattered reads switched to direct path reads. Argh! This is not what I wanted.
For reference, when a server process asks the operating system for multiple blocks at once (for example, using the system call readv) and places them into the buffer cache, Oracle records the time using the wait event facility and gives the system call a standard name of db file scattered reads. Scattered read blocks are placed into the buffer cache so other processes can also access the blocks without issuing another operating system IO request. While there is overhead when finding free buffers and placing the block into the buffer cache (which requires acquiring and holding latches and updating internal lists) when a bunch of processes are going to access the same buffer, the caching strategy generally works fantastic.
Another strategy is to have the server process read the blocks, process them in its own PGA memory, and NOT place them into the buffer cache. This is quicker for this one process because buffer cache management like finding a free buffer does not occur. Plus if a lot of blocks are being read, think large full-table scan, then perhaps we don't want to fill our buffer cache with this particular table. This is why a direct read is sometimes called a selfish read... because only the issuing process benefits. But it can make sense. Oracle's touch count algorithm (paper, book) also plays into this, but that's out of scope for this post.
The optimizer decides whether a scattered read (multi-block IO call with the results stored in Oracle's buffer cache) or a selfish direct read (multi-block IO call with the results processed in the server process's PGA memory) is performed.
So in 11g I was shocked to find my nice little load generator not generating scattered reads like I expected and wanted. So something had changed. Well, I put this on my To-Do list. But this week, I couldn't wait any longer. I'm updating my Oracle Performance Firefighting courseware and also checking many performance aspects of 11gR2, so I had to deal with this! (As in FYI, there are significant differences between 11gR1 and 11gR2.)
This is a little complicated: There are supposed to be three factors involved in determining whether a scattered or direct read should result; size of the table, event 10949, and the resurrected instance parameter _small_table_threshold. It is supposed to work like this: if the size of the table is larger then _small_table_threshold (default 996 for my 11gR2 system) AND event 10949 is set to 0 (default), then a direct read results instead of a scattered read.
But my experiments repeatedly showed when full-table scanning a 6,823 block table (8KB blocks) Oracle was issuing direct reads instead of scattered reads. Huh?... it isn't supposed to work like that.
Strangely, the instance parameter _small_table_threshold had absolutely no effect on my experiments. I set it to values like 5, 50, 500, and the default of 996 (that's right, 996) and it made absolutely no difference.
Oracle did though decide to issue direct reads when table grew to 6,823 blocks, yet 6,823 blocks seems arbitrary. Fortunately and more importantly, by setting event 10949 to 1 (using both an alter session and setting an instance parameter) I forced Oracle to issue scattered reads! So now my scattered read load generator is back in business!
In my experiments I used my OSM toolkit script ipx.sql to report on a hidden, that is, underscore parameter. All the rest is standard SQL. Here is the SQL that I ran in SQL*Plus:
set echo off feedback off verify off
connect / as sysdba
@ipx %small_table%
connect system/manager
set echo on feedback on verify on
drop table test_table;
create table test_table (c1 number, c2 char(200), c3 char(200),
c4 char(200));
declare
i number;
begin
for i in 1 .. 50000
loop
insert into test_table values (i,'a','b','c');
end loop;
commit;
end;
/
exec dbms_stats.gather_table_stats(user, 'TEST_TABLE');
select num_rows,avg_row_len,num_rows*avg_row_len tbl_size,
blocks,avg_space
from user_tables
where table_name='TEST_TABLE';
alter session set events '10046 trace name context forever, level 8';
alter system flush buffer_cache;
alter session set events '10949 trace name context off';
select count(*) from test_table;
alter system flush buffer_cache;
alter session set events '10949 trace name context forever, level 1';
select count(*) from test_table;
alter session set events '10046 trace name context off';
alter session set events '10949 trace name context off';
!ls -ltr /home/oracle/admin/diag/rdbms/prod18/prod18/trace | tail -10
I was running Oracle 11.2 on Oracle Linux 5.4.Here are the result from my experiments. Look carefully at the purple rows.
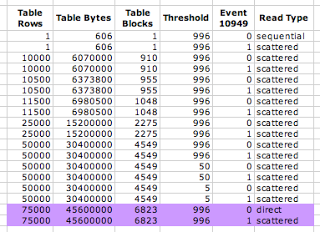
Notice the first test of 75000 rows Oracle decided to switch from scattered reads to direct reads. Whatever the threshold is, it was surpassed. (And this experiment demonstrates _small_table_threshold is not in units of rows, bytes, or blocks.) However, in the last test we took control and set event 10949 to the non-default value of 1. As a result, we forced Oracle to do scattered reads! In other words, I forced Oracle to place the blocks into the buffer cache and not do a selfish read, even when it didn't want to.
Just for reference, here is the instance parameter entry for event 10949
# 0: perhaps do a direct read for large multi-block reads (default)
# 1: always do a scat read for multi-block reads
event = "10949 trace name context forever, level 1
As a result of this experiment, when full-table scanning I can now force server processes to do scattered reads regardless of the table size (the exception is a 1 block table). So the mystery surrounding 11g and direct reads is no longer such a mystery!
Thanks for reading and I look forward to hearing from you!
Craig.