
If you have encountered the Oracle Database wait event log file sync wait event before, you know it can be very difficult to resolve. And even when a solution technically makes sense it can be very challenging to explain to others and to anticipate the impact of your proposed solution. Today I want to start exploring one of the typical log file sync solutions, including diving deep into one of the most common causes and solutions, breaking down the time components to better understand how to derive spot-on solutions, how to graphically show the situation, and how to anticipate your solution benefits before you deploy your solution in a production environment. This is a fairly large and complex topic, so I'm going to break it up into a multiple blog entry series. Thanks for joining me in this journey and let's get started!
Getting Started
But first, just what is a log file sync? It is a wait event that a server process posts when it is waiting for its commit to complete. So it's transaction commit time from an Oracle server process perspective. If you want to track commit times, then track log file sync wait times.
Every commit contains some overhead, stuff that must occur regardless of how much redo is to be written. Besides the log writer having to immediately write, various memory structures must be updated, and process communication must occur. The log writer likes to pack the log buffer blocks (sized in operating system sized blocks) full of redo entries before it writes. This makes writing very efficient. In other words, if commits are rapidly occurring the log writer is unable to fully pack each block. So if you want to increase the overhead per dml statement, just do commits very, very rapidly.
In fact, the most common root cause for log file sync being the top wait event is rapid application commits. For example, you might find the code causing the problem is essentially doing something like this:
define
i number
begin
for i 1..10000
insert into t1 values (c1,c2,c3);
commit;
end loop;
end;
The overly careful and most likely undertrained developer wanted to ensure Oracle committed after each insert. After all, they are thinking, "If I don't ensure the commit, then it may never happen!" By simply moving the commit outside of the loop, log file sync could easily no longer be the top wait event.
So one logical solution is to reduce the number of commits while still completing the same amount of work and perhaps even more! But does this really improve performance? And how? And can we anticipate the performance improvement before we actually change the production code? I decided to create an experiment.
The Experimental Results
The actual experimental code is too long to include in this blog, but can be downloaded here. You can't simply run the file. Take a close look at it. You'll notice a few grants must occur, a few objects must be created, and then near the bottom is some SQL to run the experiment, reports to view the results, and finally the raw experimental data. It's all there!
Here's the experiment design. To summarize, the experiment simply collects the amount of a single server process and instance CPU time, instance non-idle wait time, and the single server process elapsed time to insert 900000 rows at batch sizes from 1 to 16384. The batch size is the number of inserts per commit. The batch size was altered while ensuring a total of 900000 rows was inserted for each test. I ran each batch size test 35 times. Each experimental figure I refer to in this series is based on a 35 sample average. The experiment was run on a single quad core Intel chip in a Dell computer running Oracle 11gR2 on Linux.
What can we expect? Well for starters, we hope that a larger batch size (that is, rows per commit) will help increase the efficiency of each log writer write, that is, reduce the overhead per insert. Plus other commit related overhead will be reduced. So our hope is the elapsed time to complete the 900000 inserts will decrease as the batch size increases. Here are the results in table format followed by a partial data plot.
Batch Total Elapsed %
Size Rows Samples Time (sec) Change
------ ---------- ------- ----------- -------
1 900000 35 82.9945 -0.00
2 900000 35 64.9540 -21.74
4 900000 35 55.4025 -33.25
8 900000 35 50.6216 -39.01
16 900000 35 47.9620 -42.21
32 900000 35 45.0470 -45.72
64 900000 35 44.4585 -46.43
128 900000 35 44.4191 -46.48
256 900000 35 43.9992 -46.99
512 900000 35 43.7342 -47.30
1024 900000 35 43.6555 -47.40
2048 900000 35 43.5763 -47.49
4096 900000 35 43.7083 -47.34
8192 900000 35 43.5302 -47.55
16384 900000 35 43.2844 -47.85
32768 900000 35 43.1086 -48.06
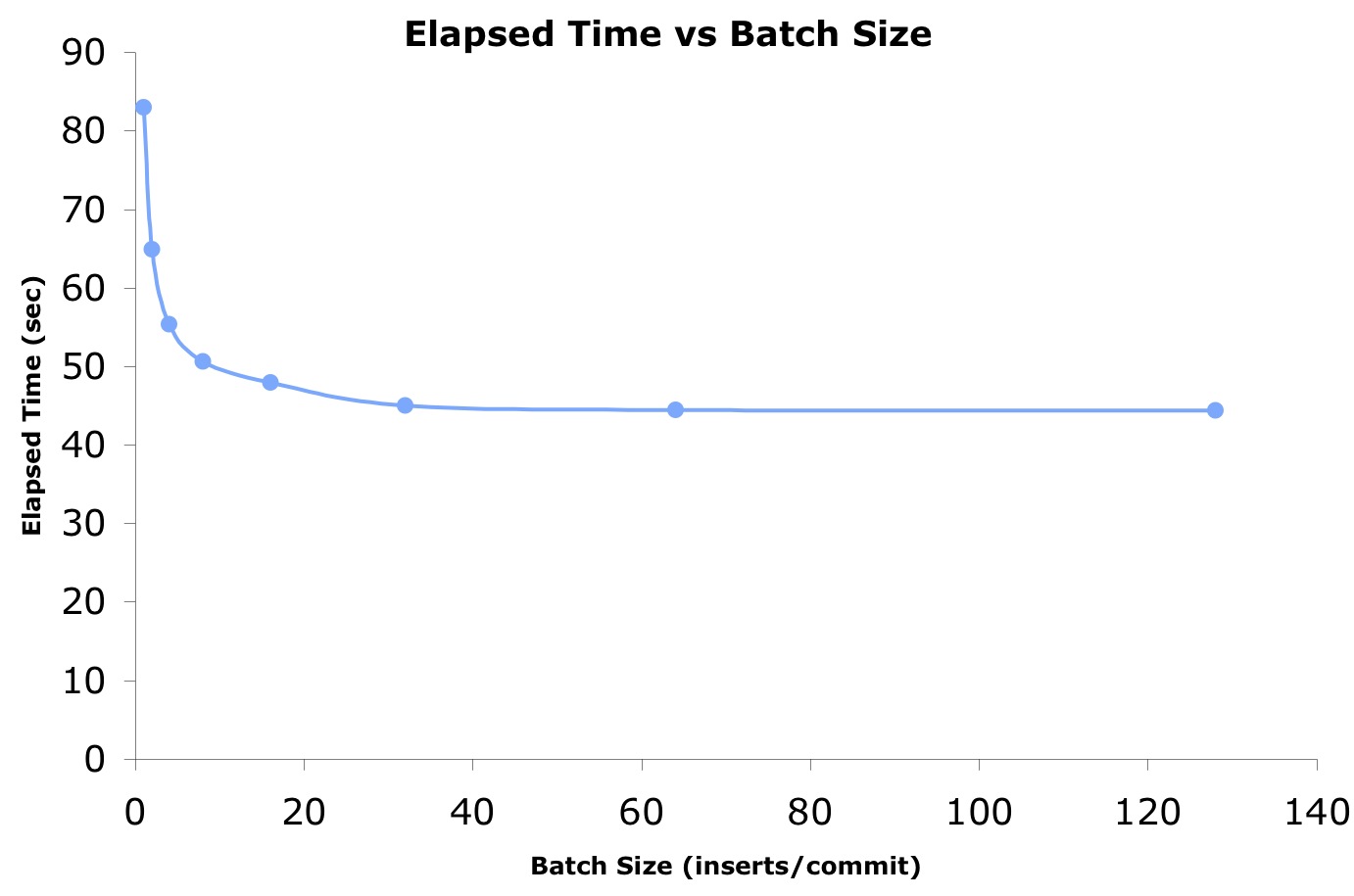
It's pretty obvious from this experiment that increasing the batch size (inserts per commit) made a massive elapsed time difference. In fact, increasing the rows per commit from 1 to only 32 resulted in a 47% elapsed time decrease! However after this, the batch size increase benefit begins to dramatically decrease to where once we hit around 33000 rows per commit only an additional 3% elapsed time decrease was seen. So creating batches in the hundreds or thousands did not make a significant difference in this experiment.
So this experiment demonstrated that (in this case) increasing the number of inserts per commit increased the number of inserts that can occur over a fixed period of time.
In part two I will break down the components of the insert time. This will help us to understand how and why batching the inserts improves performance and also sets us up to anticipate the improvement before any changes are actually made.
Here's a link or two to get the juices flowing...
Thanks for reading!
Craig.



