A while back I was developing Oracle Database predictive performance models with a customer (super senior Oracle DBA) when his phone rang. The caller said the application was taking too long to save an image and therefore there was a database performance problem. (Of course the caller knew nothing about the database but figured if there was a severe performance problem then it must be a database issue.)
My client knows Oracle Database internals and their application very well.
From an application perspective, saving an image means an Oracle Database commit time plus the time related to the data flowing through a complex series of routers, application servers, web servers, security processes, and on and on. So he ran a simply query comparing the previous and current day Oracle Database event log file sync wait times. He figured that if there was a significant difference in log file sync wait times, then the problem could be Oracle database related. And if the log file sync wait times where the same, then the problem was likely to reside somewhere else.
Why did he compare log file sync times when the reported problem was saving an image? The answer is because log file sync wait time changes are a fantastic indicator of database commit time changes. Plus knowing log file sync wait times enables a good database commit time approximation. Exploring the relationship between commit time and log file sync wait time is what this blog entry is all about.
What is a log file sync wait?
When a client process issues DML such as an update, delete, or insert by the time control is returned to the client process the associated server process ensures the appropriate database buffers have been changed and the resulting redo is in the redo log buffer (not log, but buffer). Both the block buffer changes and their associated redo buffer entries must complete or the entire statement is rolled back.
When a client process issues a commit a number of things must occur and they must occur in the correct sequence. Both the server process and the log writer require CPU and IO resources to complete their tasks plus they must communicate to coordinate their individual tasks. Their CPU consumption can be tracked via the v$sess_time_model view and their wait time can be tracked via v$session_event. When the client process receives the "commit complete," from Oracle's perspective the redo now resides on an on-line redo log and both the server process and the log writer are synchronized. (One exception is when Oracle's commit write facility is being used.) When a client process issues a commit and if its server process must wait for the log writer to complete some work (CPU or IO) before the server process can continue, the server process will post the wait event log file sync.
Because significant CPU and IO resources are required for a commit to complete, significant log file sync wait times can occur with either a CPU or IO operating system bottleneck.
Keeping all this in mind, it follows that if log file sync wait times have increased, it is highly likely commit times have also increased. While this makes sense, is it really true? And are there creative ways to use this knowledge? Read on...
Is there a correlation?
More specifically, is there a correlation between database commit times and log file sync wait times? As my experiments indicated, there is indeed a strong correlation.
Here's the core experiment setup:
commit (the "initial commit")
insert some rows
let the system stabilize
get wall time, log file syncs and log file sync wait time for session
commit (the "timing commit")
get wall time, log file syncs and log file sync wait time for session
I created three experimental variations. The first variation is a single process performing the above with a four second stabilization time. I also varied the number of inserts per commit from 1 to 10000. I call this the batch size. For the second variation I simply eliminated the stabilization time, which created a very intense serial process. The third variation used a stabilization time of two seconds and I added ten other concurrent processes that inserted, commited, deleted, and commited a single row...repeatedly. To avoid table related concurrency issues, each concurrent user worked on a different table. For each insert batch size change, between 90 to 100 samples where taken. I also measured the overhead of the timing collection for both the log file sync wait time and the wall time (which is our commit time), and then subtracted that from the results. One reason I took so many samples was because the wall time collection overhead varied significantly.
Here is a code snippet used to gather performance data:
begin
select total_waits,
time_waited_micro,
to_char(systimestamp,'YYYYMMDDHH24MISSFF')
into :waits_total_1,
:wait_time_micro_1,
:cur_time_1
from v$session_event
where sid=:mysid
and event='log file sync';
end;
/
Now for the results.
The first variation included a four second delay after the initial commit was issued. This allowed the system to calm down to reduce the likelihood that the second commit, which is timed, was being impacted by previous work. The correlation between commit times and log file sync wait times was a staggering 1.000, with 1 being a perfect correlation. This means when log file sync wait time increased, so did the commit time. Including all the 1170 samples, 87% (stdev 6.2) of the commit time was due to log file sync time. When the insert batch size was one, 77% of the commit time was due to log file sync time. The numerical and graphic results are shown below.
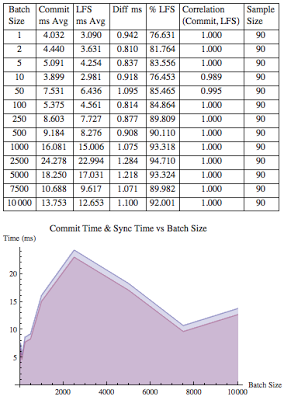
For the second variation I removed the four second delay. This creates an intense serial server process load on the system. Fortunately, because of Oracle's background processes, even though there is a single server process involved the log writer background process is involved providing much needed parallelization. As with the first experimental variation, the correlation between commit times and log file sync wait times was a staggering 1.000. And when considering all 1300 samples, an average 76% (stdev 17.7) of the commit time was due to log file sync time.
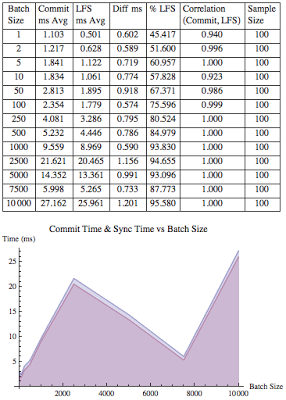
Notice that when the insert batch size was one, log file sync wait time accounted for only 45% of the commit time. Yet when the insert batch size was 10000, log file sync wait time accounted for 96% of the commit time. Regardless of the insert batch size there is some commit related work that must always occur. This overhead can be roughly calculated as the difference between the commit time minus the log file sync time. As our experiments demonstrate, as the insert batch size increases, this overhead takes less and less time per insert. But when the batch size is only one, this overhead took nearly 55% of the commit time. This is why it is much faster to issue 100 updates followed by a single commit compared to doing 100 update and commits. If you want to dig into this topic and actually quantify and predict, check out my blog entry entitled, Altering insert commit batch size.
The third variation incorporated concurrency into the situation. While there was a two second stabilization delay used in the statistics gathering process, the other ten concurrent processes had no delay. They simply and repeatedly inserted a row, commited, deleted, commited, repeat! This is the classic strategy for causing intense log file sync waits. In fact, looking at the experimental results below you can see the average log file sync times are over 800ms. If this was a real OLTP centric system, users would probably be irate!
For this experimental variation, the correlation between commit time and log file sync time was a respectable 0.76. On average around 73% of the commit time was due to log file sync wait time. While the percentage is in the same range as the other experimental variations, because the commit times are much longer, the actual time difference was a few hundred milliseconds not around a single millisecond.
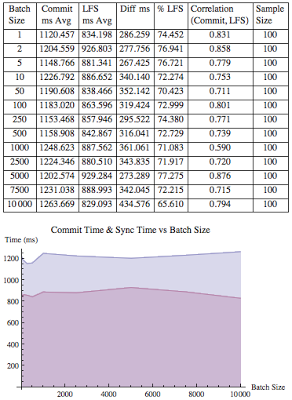
It's important to understand in this experimental variation there is: a single log writer working in conjunction with multiple server processes, each server process must communicate and properly coordinate activity with the log writer, and they all must share resources. As a result, depending on the OS bottleneck, CPU core speed, and IO subsystem speeds, the difference in commit times and log file sync times can vary significantly. What I'm trying to say is that how I designed the experiment and the hardware I was running (Linux with 4 CPU cores and a single IO device, Oracle 11gR2) can effect the specific timed results. But regardless of these things, 1) at no time did the log file sync time exceed commit time. Technically I can't see this ever occurring and it never occurred in any of the experiment's 3,770 samples. 2) There was always respectable correlation between commit time and log file sync time, and 3) log file sync time is a very significant part of the overall commit time.
What does this mean in my work?
What does this mean in practical daily DBA performance analysis work? When commit times increase you can expect log file sync wait times to increase. And if log file sync times come to within around 75% of your commit time SLA, you have most likely breached your service levels. So it turns out my colleague's strategy of comparing log file sync times from the previous day to the current day was right on the money! And in his situation, the performance problem turned out to be a problem with the application servers, not the database server!
Is log file sync time a reasonable commit time approximation?
Yes log file sync wait time is a reasonable commit time approximation, but it is even a better predictor of commit time. In these experiments the log file sync time averaged 73%, 76%, and 87% of the total commit time. Knowing the average log file sync wait times, you can expect your commit times to around between 10% to 25% longer. More practically stated, if your log file sync wait times are approaching your commit time SLAs, you can count on your commit time SLA being breached. Creatively applying this knowledge, instead of instrumenting a user application to gather and monitor commit times, you could use Oracle's wait interface to monitor log file sync wait times instead!
So knowing log file sync times can be very valuable in both performance monitoring and performance firefighting.
Thanks for reading!
Craig.



