The Situation
In my performance work I often am presented with a Statspack or AWR report. After performing my 3-Circle Analysis the key SQL statement(s) is easily identified. Obviously my client and I want to know key characteristics about that SQL statement. The standard reports presents me with only total values such as elapsed time, executions, physical IO blocks read, CPU consumption, etc. that occured during the report interval. From an elapsed time perspective, all I can determine is the average elapsed time...not a whole lot of information and as I'll detail below, it has limited value and can easily cause miscommunication.
The problem and my desire
I find that in communicating using only the average SQL elapsed time my audience makes a number of assumptions which, are many times incorrect. Plus I simply cannot glean very much from what the standard reports present. This is another way of saying my communication skills need some work and I need more data! I want to better understand, describe, and communicate SQL statement elapsed times. So in essence, my desire is to be able to responsibly provide more information with very limited inputs.
The value of a conforming SQL statement
Now if a SQL statement elapsed time conforms to a known statistical distribution, then with minimal inputs I will be able to responsibly say much more, communicate better, and serve my clients and students better. But even if it does not statistically conform, if a general pattern develops I may be able to say something like, "The typical elapsed time will most likely be much less than the average." Just saying that will be valuable to me.
It's not normal
Last November I blogged about how given an average value, most DBAs will assume a value is just as likely to be greater than or less than the average. This is another, albeit very simplified and not entirely true, way of saying the samples are
normally distributed. One of my objectives in the initial "average" blog entry was to demonstrate that Oracle's wait events are not normally distributed. For example, given the average db file scattered read wait time of 10ms, it is highly unlikely there are just as many waits greater than 10ms as there are less then 10ms. What we clearly saw in that blog entry was that more wait occurrences took less than 10ms than longer than 10ms. In this blog entry we'll take a giant leap forward.
Check This Out For Yourself
I spent quite a bit of time preparing this blog entry. In part because I want others to be able to do exactly what I have done, that is, to check this out for themselves. So I created a tool kit that anyone can use to investigate what I'm writing about on their systems or they can use the tool kit on their test system using sample data the tool kit quickly generates.
While all the actual data samples and the associated analysis tools in this blog entry can be found here, the data collection tool kit used to gather the sample data can be downloaded, installed, and used for free. To get the tool kit, go to http://www.orapub.com and then search for "sql distribution". Here's a link to help you get started.
The Experimental Design
This experiment requires two Oracle users each with their own Oracle SQL*Plus connection: the monitoring user and an application user. You can run this yourself (test or production system) and see the details by downloading and using the tool kit. The monitoring session quickly and repeatedly queries from v$sqlstats looking for refreshed rows related to a specific SQL statement, which is uniquely identified by its sql_id and plan_hash_value. The algorithm creatively (it's pretty cool, check it out) determines when the statement begins, ends, and also collects timing and resource consumption details.
It is limited however; to simplify the data collection strategy, concurrent executions are averaged when they complete. To mitigate this factor, the chosen SQL statements where somewhat unlikely to be executed concurrently. Also, to reduce the likelihood of bogus data being recorded, in some cases potentially incorrect samples are discarded. My data collection tool is clearly not the ultimate, but it's the best I have at the moment and I have taken specific steps to reduce the likelihood of bogus data being part of the final experimental sample set.
The results are inserted into the results table, op_sql_sample_tbl. When the data collection has finished, a simple query formats the results so they can be easily understood and also will feed nicely into a Mathematica notepad for analysis. The notepad file is also provided in the tool kit.
Below is an example of what a run result can look like. For readability I replaced the real sql_id and plan_hash_value with abc and 123 respectively.
def sql_id_in='abc'
def hash_plan_value_in=123
def collection_period=60
set serveroutput on
exec get_sql_sample_prc(&collection_period,0,'&sql_id_in',&hash_plan_value_in);
set tab off
set linesize 200
col SQL format a25
col sample format 999999
col PIOR_exe format 999999999.0000
col LIO_exe format 999999999.0000
col CPU_ms_exe format 999999999.0000
col Wall_ms_exe format 999999999.0000
select sql_id||','||plan_hash_value SQL,
sample_no sample,
executions execs,
disk_reads/executions PIOR_exe,
buffer_gets/executions LIO_exe,
cpu_time/executions/1000 CPU_ms_exe,
elapsed_time/executions/1000 Wall_ms_exe
from op_sql_sample_tbl
order by 1,2;
SQL SAMPLE EXECS PIOR_EXE LIO_EXE CPU_MS_EXE WALL_MS_EXE
-------- ------ ----- ----------- ----------- --------------- ---------------
abc,123 1 1 46071.0000 69023.0000 847.8710 992.2190
abc,123 2 1 46071.0000 69023.0000 830.8740 838.2920
abc,123 3 1 46071.0000 69023.0000 854.8690 855.4500
abc,123 4 1 46071.0000 69023.0000 809.8780 827.9930
abc,123 5 3 46067.0000 69023.0000 840.5387 925.5117
abc,123 6 1 46070.0000 69023.0000 853.8700 1171.6570
abc,123 7 1 46070.0000 69023.0000 845.8720 847.1400
abc,123 8 1 46070.0000 69023.0000 840.8720 1049.0460
abc,123 9 2 46067.5000 69023.0000 861.8690 1115.8440
abc,123 10 1 46070.0000 69023.0000 849.8710 1372.9310
abc,123 11 1 46070.0000 69023.0000 838.8720 843.6460
abc,123 12 1 46065.0000 69023.0000 852.8700 860.7630
Without access to Mathematica to you can quickly create a histogram by selecting the wall_ms_exe column, placing the values into a single line separated by commas, enclose the line in curly braces, pasting that into http://www.wolframalpha.com and pressing the "=" submit button. Here's what I mean:
{992.219, 838.292, 855.45, 827.993, 925.511667, 1171.657, 847.14, 1049.046, 1115.844, 1372.931, 843.646, 860.763}
Even with this limited sample data set above from one of my test systems, you'll get tons of statistical data including the below histogram I snipped from the WolframAlpha's on-line result page.
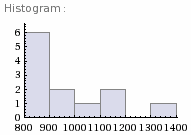
(I'm still amazed WolframAlpha is on-line and for free.) I will explain the results in the below analysis section.
Real Experimental Results
Real Production Data
While I could have used data from my in-house test systems, for this experiment I wanted to use real SQL statements from real production Oracle systems. I found two volunteers who, using my tool kit, gathered data for a number of SQL statements. A profound thanks go out to Dave Abercrombie and Garret Olin, who have both provided me with real performance data, and in the past as well! Dave is also my Mathematica mentor and statistical Jedi Master. He also writes a very insightful blog you may want to follow. While both Dave and Garret have helped me in this quest, they are in no way responsible for any mistakes or botches I may have made.
Lots of Production Data
Even using the snippet of data above along with WolframAlpha you get the gist of the experimental results. But as I demonstrated in my Important Statistical Distributions blog posting, looks can be deceiving! Plus it's always nice to get lots of data. I asked Dave and Garret for at least a hundred samples. This reduces the risk of anomalous data making a significant impact...not to mention people decrying the conclusions as bogus and insignificant.
Statistical Distributions
Before I get into the analysis of the experimental results, it's extremely important to understand a histogram, five common distributions, the histograms for these distributions, and a few key characteristics of each. These key statistical distributions are uniform, normal, exponential, poisson, and log normal. If you are not familiar with these, please reference my blog posting about Statistical Distributions. That blog entry was originally part of this post, but it grew too large and can stand on its own.
Analysis of Experimental Results
My colleagues collected four SQL statements from OLTP systems. I performed statistical fitness tests checking to see if the sample sets, statistically speaking (alpha=0.05) conform to a normal, exponential, poisson, or log normal distribution.
Statistically speaking, all four sample sets did not match any of the above distributions.
In every case, the log normal distribution was the closest match, but still it was not even close to statistically conforming.
If you want to check out the statistical work which includes lots of comments, math, and graphs, you can download the Mathematica notepad, a PDF of one of the experiments, data sets, etc. by clicking here. It's pretty cool.
Initial visual test passed nearly every time
I want to demonstrate just how easy it is to be deceived. The below histogram was taken from one of the four elapsed time sample sets (ref: Garr 8q, 97% of histogram data shown).
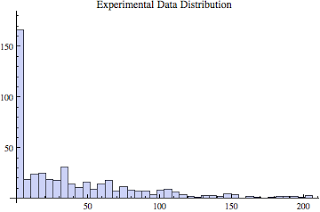
Looking at this histogram, the data looks exponential, perhaps poisson or log normal. This sample data failed to match all of these distributions. Not only did the hypothesis test fail, but it was not even close! My lesson from this is, the next time someone tells me the histogram represents data that is exponentially, poisson, or log normal I will kindly demand to see the fitness (statistical hypothesis) test comparing the experimental data with the stated fitted data distribution.
By the way, if you recall in Important Statistical Distribution blog entry about if the sample data is log normal, you can take the log of each sample, place it into a histogram, and the resulting histogram will look normal. Well...using the data from the above histogram, I did just that and the histogram below was the result!
![]()
This is a visually clear sign that our data set is not log normal distributed! But looking at the experimental data histogram we could not visually determine this. Personally, I find this very interesting...but time constraints did not allow me to delve deeper.
Beware of bind variables!
The data collection processes identifies the statement based on the combination of a sql_id and plan_hash_value. That's good because there can be many plans for the same sql_id. This allows us to differentiate between execution plans! However, there can also be many bind variable combinations applied to the same execution plan! If you see multiple clear histogram peaks (modes), there is likely a different bind variable set(s). There can also be multiple bind variable sets that result in the same elapsed time. This will effectively stack a histogram bar. Based on my conversations with the data provider of the image below, he knows there are multiple bind variable sets related to the same execution plan. The below histogram confirmed what he thought was occurring.
Of the four data sets I received, there was one that I believe is actually far more common then we suspect. It's histogram is shown below (ref: Aber 31, 90% of histogram data shown).
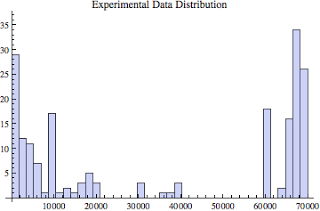
This histogram above shows the elapsed times for a single SQL statement with a single execution plan, yet with what looks to be two or three different bind variable sets. Notice there are at least three clear modes (peaks); near zero, near 10000 ms, and near 70000 ms. The actual average elapsed time is around 57200 ms. Is stating the average elapsed time is 57.2 seconds a good way to communicate the elapsed time? If I added the standard deviation is 104 seconds and we have 230 samples, it's obvious elapsed time ranges are all over the place and of course, never go negative.
A better way to communicate the analysis is that user will tend to either have results returned around 10000 ms or around 70000 ms, but probably not around the average of 57200 ms. There is a huge difference between 10 seconds and 70 seconds. Depending on your audience, actually showing them this histogram will immediately convey the complexity of the situation. My point is, unless we actually gather the detailed data and plot a histogram, describing the situation in terms of average can easily mislead your audience.
Profiling
This also brings up another point. If I'm going to profile the SQL statement to tune it, which bind variable situation am I tuning for? Can I tune for both? The profile is likely to look very different based on the bind variables. I used to do a lot of SQL tuning and when I did, I always demanded real bind variables and I made sure everyone new the bind variables I was using. Even then I new that, when we go for 100% optimization, there are likely to be big winners...and also big losers. So we've got to be careful. Having a histogram of the actual elapsed time can help us understand the true situation.
Predictive possibilities
There is good news and there is bad news... I thought for sure the experimental data would statistically conform to either the exponential, poisson, or log normal distribution...but it wasn't even close. The big disappointment is I cannot predict the median (or other statistics) based only on the average SQL elapsed time. But the results are what they are.
While the comparison between the data sets and the distribution did not statistically match, in every case unless bind variables caused a massive difference in the elapsed time, the median is far less then the mean. And if I assume the data is log normal distributed, the predicted median value was higher then the actual median. That is, if I predict the median, the actual median is probably lower. Said another way, if the average is 1000 ms and the predicted median is 50 ms, the actual median is probably less then 50 ms and what the user is more likely to experience.
Pick one of your Statspack/AWR SQL Statements
Now let's apply this to a real life situation. Referencing one of my cleansed Statspack reports and then looking at the reported top CPU consumer, I see the following statistics during the one hour sample period/interval.
CPU CPU per Elapsd Old
Time (s) Executions Exec (s) %Total Time (s) Buffer Gets Hash Value
---------- ------------ ---------- ------ ---------- --------------- ----------
14456.36 7,000 2.07 86.3 497518.80 1,182,585,272 314328380
Over the one hour sample interval this SQL statement was executed 7000 times which took about about 497518.80 seconds in total, that is the wall time or the elapsed time. This means that during this one hour sample period and for this SQL statement, the average elapsed time was 71.1 seconds.
If the statement is using a single bind variable set or the bind variables are not causing wild elapsed time swings, then you would expect the typical elapsed time to be less then 71 seconds and perhaps around half that. We can also expect the elapsed time to occasionally be much longer than 71 seconds.
If I needed more specific and more useful data, then I would use my data collection script to gather some data, plug it into my Mathematica analysis notepad, and crank out the histogram.
Unfortunately, because our analysis could not match the experimental data with a known statistical distribution, we can not confidently and responsibly make precise predictions about the expected median and other statistics. That's too bad, but that's the way it is...for now.
If you really want to know...
If you want to sincerely understand the elapsed time characteristics of a key SQL statement, then you will need to gather some data. Running the statement a few times from within the application or perhaps using SQL*Plus will get you some results, but that is not what we are looking for here. We want to see the elapsed times for the SQL statement as it occurs in your real production system. The best way to do this is through some automated tool. But what tool?
Whatever that tool may be, it must gather multiple individual elapsed times and then draw conclusions. Gathering the number of executions and the total elapsed time, even within an 30 minute interval, will only provide the average...and that's not what we're going for here.
You could use my tool that my colleagues and I used to gather the data which I analyzed. But the sampling method (and to get the best samples) nearly 100% consumes a CPU core...not what I would call a production ready product! If I come up with a utility to gather this type of data with minimal overhead I'll be sure to blog about it and offer it to other DBAs.
Conclusions
Based upon my analysis I think it is reasonable to assume given a SQL statement (the text, that is, the sql_id) its elapsed time will not conform to any common statistical distribution. Why? Because for a given SQL statement there can be multiple execution plans and within each execution plan there can be multiple bind variable combinations. Even if you can demonstrate the SQL being investigated is running with the same execution plan and with the same bind variable set, as two of my sample sets showed, the elapsed times varied wildly and did not conform to the normal, exponential, poisson, or log normal distribution. While the distribution may look log normal, statistically it didn't pass the hypothesis test.
Here's a few points that I will take away from this specific work: While this experiment did not prove SQL statement elapsed times do not conform to a standard distribution, it certainly raises the question they may not conform. Why? Because every sample I have analyzed has shown its elapsed time distribution is not statistically normal, poisson, exponential, or log normal distributed. If someone states otherwise, respectfully ask to see their data and subsequent analysis.
Unless a SQL statement is using multiple bind variable sets, I would be very comfortable stating the median is less and possibly considerably less then the mean. All our analysis data sets (and my experimental ones also) show the median is far less then the mean. At least by 50%.
Just because a data set visually looks very much like another data set or statistical distribution, does not mean it statistically matches...be careful.
If you really want to know the elapsed time characteristic of a key SQL statement, you must actually gather elapsed time samples...and lots of them. If you don't have access to Mathematica, send me your data and I will gladly perform the analysis for you!
I learned a lot from preparing this blog entry: My math skills have certainly increased, especially regarding hypothesis testing. My Mathematica skills have also dramatically increased...this can be seen by viewing the notepad file I developed and used to analyze the data. Developing the data collection tool kit was very satisfying and I've already used to it to create another similar tool and I'm considering developing an advanced product version (stay tuned). My SQL elapsed time assumptions were where seriously brought into question. I was able to come away with stronger conclusions about the typical SQL elapsed time then I could previously. Not a hunch, but based on a solid statistical analysis.
Thanks for reading and I look forward to receiving data samples from you!
Craig.




{kind=link}