If you have been following my recent posts and especially the post about Oracle Database SQL statement elapsed times, you'll know that unfortunately SQL statement elapsed times do not conform to a normal, poisson, exponential, or even a log normal distribution. That's unfortunate because if a statement does indeed conform, even with limited data (which we can easily obtain), we can make some pretty amazing predictions. But still, I was able to come to some useful conclusions. In this posting I want to investigate the pattern of Oracle Database SQL statement arrivals.
Why Should We Care?
Note: If the below terms are not familiar to you, I will clearly define them starting in the next section.
Arrival rates and inter-arrival times are a massively important topic in computing system performance analysis. In the capacity planning and predictive analysis industry it is a given that the pattern of inter-arrival times (time/work: ms/trx) is exponentially distributed and the average arrival rate (work/time) is poisson distributed. [1, 2, 3] This is so ingrained into minds that if I went to a non-Oracle computing performance conference and suggested otherwise, I would immediately be questioned, demeaned, and have pencils thrown at me (or something like that). It wouldn't be pretty.
But to believe science is unscientific, is it not? And what is wrong with challenging assumptions about Newton's Three Laws of Motion, that we live in a closed system, and even perhaps question arrival pattern assumptions? I got flack from the "experts" when I first start speaking about Oracle's wait interface and when to use an index. And even now I still get some flack regrading how to apply classic response time analysis to Oracle time-based analysis. And being called dangerous is actually pretty cool, especially when you look at who's saying it!
But in all seriousness, my objective in this posting is simply these three things:
To test and create the ability for others to test; are SQL statement arrival patterns exponential? And if not, do they conform to some known statistical distribution? What can I learn that will help me in my daily performance analysis work?
That's my objective, pure and simple.
The Plan
To ease you into this topic, I'm going to start with defining a few key terms with words and pictures. Then I'll summarize the experimental design, how I collected the data, an analysis of three data sets, and then I'll draw some final conclusions. I will also provide the links so you can perform the same tests I have. I hope you enjoy the journey!
Transaction Arrivals
Average Arrival Rate
Let's say you went to your local shopping mall, sat down in a nice cushy chair, and counted the number of people who walked into a specific store over a one minute period. Perhaps 21 people went into the store. Don't mean to insult your intelligence here, but this means 21 people arrived into the store over a one minute period. So the arrival rate is 21/1 people/minute or 21/60 people/second or 0.350 people/second. This is known as an average arrival rate.
An arrival rate needs a unit of occurrence or work and a also a unit of time. Examples of occurrence or work are a transaction, logical IO, physical IO read, physical IO read request, an execution of SQL statement ABC, or procedure customer_add. Examples of time are hours, seconds, etc. While this may seem trivial, when referring to the arrival rate it is important to always keep the occurrence as the numerator and the time as the denominator. One reason is because the inter-arrival time is naturally given in time per occurrence and most of this blog is specifically referring to the inter-arrival time. So always listen close and use the unit of occurrence and time carefully.
Now that we can calculate the average arrival rate, let's take this topic to the next level...inter-arrival times.
Inter-Arrival Times
This topic really starts with inter-arrival times. The inter-arrival time is simply the time between each arrival. For example, taking a slight yet significant twist from the above shopping mall example, suppose I wrote down the time of each arrival. Not the number of people that arrived over an interval of time, but the time of each arrival. It's then a simple task to determine the time between each arrival, that is, the inter-arrival time. Let's say the shopping mall inter-arrival time (sec/person) data looked like this:
{49.4135, 24.9792, 9.40843, 6.01274, 4.25393, 20.0842, 6.33593, 79.0265, 34.7396, 75.3667, 35.4444, 36.2891, 46.6725, 1.66213, 21.2452, 1.8656, 19.2686, 7.79427}
If I take this data set and paste it into WolframAlpha (did it here), one of the results is this histogram.
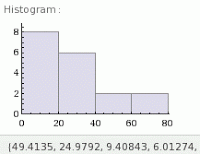
The industry expects inter-arrival times for computing system transactions to be exponential, but how about the data above? If you have followed my blog entry on statistical distributions you'll know that this could be exponential, poisson, or log normal. Even if we had more samples, if I creatively alter the bin sizes I could make the histogram look just about anyway I wanted. What we need to do is a statistical hypothesis test. I'm not going to do that here, but I will with the real experimental data below.
Suppose I sat like a couch potato at the shopping mall until I ended up with 100 samples, not just 18 as above. The resulting histogram looks like this:
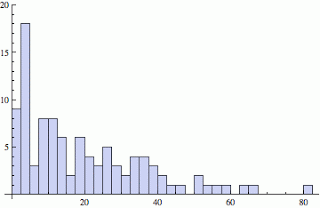
The two histograms look physically different because the just above histogram was created using Mathematica... WolframAlpha doesn't like me pasting 100 samples into it. Three points: The average is 19.7, the median is 14.4, and while the distribution looks log normal, it is exponential because I created it that way (sorry...kind of sneaky I know).
By industry definition, transaction inter-arrivals should be exponentially distributed. [1, 2, 3] There is also another accepted assumption regarding the inter-arrivals; they are expected to be independent of each other. Referring to my shopping mall example: If I'm at a mall with my wife, if she walks into Lucy's I will likely follow! My arriving was dependent on her arrival, so our arrivals are clearly not independent. Family's walking into restaurants are another dependent example.
With the knowledge of inter-arrivals, dependent vs independent arrivals, and the accepted industry assumption, let's now look at the pattern and the average of inter-arrivals.
Inter-Arrival Average and Pattern
Let's explore how the arrivals visually appear on a time line. This is a fantastic way to grasp the fact that it is entirely possible for inter-arrival average times to be the same but the pattern of arrivals be different. The pattern of inter-arrivals above was exponential, but what does that pattern and other patterns look like on a time line?
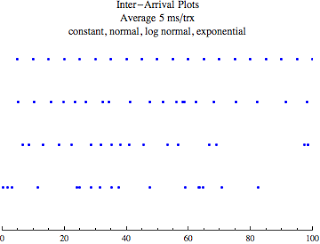
If you need a quick statistical distribution refresher, I blogged about this topic here.
The image above shows four different inter-arrival patterns, each with the an average inter-arrival time of 5 ms/trx. The top time-line is a constant inter-arrival rate (a perfect uniform distribution), that is, every 5 ms another transaction arrives...if only we were so lucky! The second from top time-line shows transactions arriving in a normally distributed pattern, with the average inter-arrival time of 5 ms along with some variance. In fact, I have defined the standard deviation to be 2. The third from top shows transactions arriving in a log normal distributed pattern, with the average inter-arrival time pulled from a normal distribution with an average of 5 ms and the standard deviation of 2. (Confused? Read this blog post.) The fourth from top, that is, the bottom time-line shows transactions arriving in an exponentially distributed pattern with the average inter-arrival time of 5 ms. As you can see, there is more to arrivals then just the average...the pattern is also very important.
So important in fact, we can feel the difference! If you worked the counter at a fast food restaurant, which arrival pattern would you prefer? If you choose, exponential (bottom line) your nuts because sometimes you would be sitting around doing nothing while other times there would be people queued up and glaring at you! Most people (including our users) desire smoothness and predictability and so a constant (that is uniform) inter-arrival rate is what we like. When we analyze the experimental data, we'll get a picture of real Oracle SQL statement inter-arrival times!
OK, I'm done with the background information. Now it's time to delve into what is really happening in production (not the lab) Oracle systems.
Experimental Design
To demonstrate the pattern of SQL statement inter-arrivals I needed to create an experiment. I also wanted it to be easily performed by others in their production environments. I created a data collection script that will gather the inter-arrival times for a specific SQL statement (and specific plan) and record the results in an Oracle table for easy manipulation and retrieval. I also created a Mathematica based notepad to perform the statistical analysis. The analysis is essentially a hypothesis test to determine if the collected inter-arrival times conform to a standard statistical distribution; normal, exponential, poisson, or log normal. Before we analyze the results, I need to describe how the data is collected.
Data Collection
How the data is collected is key to this experiment. If I botched anything in this experiment, it would be the data collection. It's tricky to get good inter-arrival times. To simplify the situation, the collection works better under certain circumstances. If the same SQL statement is not waiting to be run by multiple sessions, it appears I can adequately determine when a SQL statement arrives by looking at it's execution start time, which will also be close to when v$sqlstats inserts the first row for the statement or updates (i.e., refreshes) its existing row.
As I demonstrated in my When Does V$SQLSTATS Get Refreshed posting, for SQL statements the execution column in v$sqlstats is incremented when the statement begins (worst case when parsing ends). Therefore, when detecting an execution count change, we know the SQL statement has begun and therefore arrived. The arrival time is logged in the op_results_raw table.
Click here and you can view a text file that introduces the experiment, shows the actual collection and extraction code, and step-by-step how to perform the experiment yourself. I also include some sample data that was taken from one of my test systems.
The collection procedure samples from v$sqlstats in a tight loop (you can insert a delay however) and when the execute count changes, the time is recorded in the op_results_raw table. The collection procedure does not query from the v$sqlstats underlying x$kkssqlstat fixed table because this may limit your ability (think: security issues) to collect the data. However, if you wanted, all you would need to do to use x$kkssqlstat is simply substitute the object name in the collection script and of course, connect as sys when you collect the data.
The collection procedure, get_sql_arrival_rate_prc takes four parameters.
sample_secs_in is the number of seconds to sample from v$sqlstats.
delay_secs_in is the number of seconds to sleep between samples. Setting this to zero will give you the best data. However, without a delay the sampling script will likely consume 100% of one of your CPU cores. So be very careful! Changing the delay parameter from 0 to 1 can make a big difference in the monitoring procedure's CPU consumption.
sql_id_in is used, in part, to uniquely identify the SQL you are interested in understanding its arrival pattern.
plan_hash_value_in is used, in part, to uniquely identify the SQL you are interested in.
Let's assume I want to sample without any delay for 60 seconds looking only at the SQL statement with a sql_id of acz1t53gkwa12 and a plan_hash_value of 4269646525. This is one way to setup running the procedure and then doing so:
def sql_id_in=acz1t53gkwa12
def plan_hash_value_in=4269646525
def sample_duration_secs_in=60
def delay_secs_in=0
alter session set commit_write="batch,nowait";
set serveroutput on
exec get_sql_arrival_rate_prc(&sample_duration_secs_in,&delay_secs_in,'&sql_id_in',&plan_hash_value_in);
To reduce the overhead of inserting the experimental data into an Oracle table, I utilize Oracle's commit write facility. I reference the commit_write setting on page 302 in the fourth printing of my book, Oracle Performance Firefighting and also discuss this in performance firefighting course as well. This is a perfect use for the facility.
After the 60 seconds I should have some rows inserted into the op_results_raw table. I show a number of short SQL statements in the experimental text file (again, click here to download) which, to not bore you death, I do not show here. But what I'm really interested in is the list of inter arrival times. For example, in one of my sample runs on an experimental system, here is the first 19 inter-arrival sample times (in seconds).
1.017546,
1.01921,
1.018855,
1.106451,
1.01858,
1.018235,
1.017525,
1.025062,
1.023676,
1.02267,
1.026292,
1.026526,
1.023412,
1.019862,
1.018121,
1.018232,
1.107351,
1.045038,
1.01754,
With only a few values, I can call on my good friend WolframAlpha to quickly and easily create a histogram. All I need to do is remove the ending comma, enclose the list of values in curly braces, go to www.wolframalpha.com, copy and past in the list, and submit the request. In a couple of seconds, Mr. WolframAlpha will present me with, among other things, the histogram shown below.
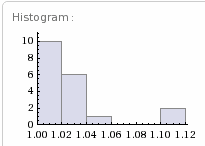
What type of distribution does this look like; constant, normal, random, exponential, or some other?
So that's how the experimental data was gathered and I'm hoping you'll be motivated to do the same. Let's move on to two actual production collections and then make some final conclusions.
Analysis of Sample Set One
Data Set: DaveB-OLTP-1
Note: You can download this full analysis in pdf format here. It is the Mathematica notepad (printed to PDF) used to analyze the data including the statistical hypothesis testing and plenty of graphs. I also liberally commented the notepad so both you can I can follow along.
The SQL statement comes from a production OLTP intense Oracle system. Over the 60 second sample period, the SQL statement was executed 321 times, hence we have 321 samples. Numerically, the average inter-arrival time was 186.8 ms, median 59.1 ms, standard deviation 1384.8 ms, with a minimum value of 0.135 ms and a maximum value of 19182.7 ms. Talk about variance! Notice the median is less than half of the mean. If was to randomly select one of the sample inter-arrival times, I'm likely to pick a value around the median. Said another way, the inter-arrival time is more likely to be around 59 ms than 187 ms.
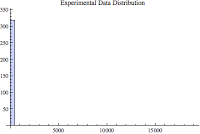
While clearly not visually exciting, above is the histogram for the entire data set. (The horizontal axis unit of time is microseconds.) It clearly shows our data is massively dispersed. Why? Two simple reasons: the only reason the horizontal axis goes out so far to the right is because there are actual sample values out there...just not that many of them! Plus the maximum value sample would be placed near the far right horizontal axis around 190,000 micro-seconds. These far-right samples are not anomalies, but actual sample values and you'll see that they appear in all three data sample sets...so I'm not going to ignore them. They force me to understand that while the relatively massive inter-arrival times are indeed rare, they are so massive they effectively pull the mean (187 ms) away and to the right of the median (59 ms). However, I am also interested in the bulk of the data, so I created another histogram.
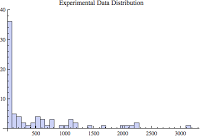
Because of the massive dispersion of the data (difference in min and max values), showing all the data limits our ability see where and how most of the samples values group. The above histogram shows 95% of the data. It's the top 5% (and perhaps less) that contain the massive inter-arrival times. Because there are 321 samples and the above histogram contains 95% of the smallest values, the above histogram contains 305 samples (perhaps 304...I didn't count).
Does this inter-arrival sample set conform to the normal, poisson, exponential, or log normal distribution? Visually it sure doesn't look like it! And our hunch is correct. The statistical fitness (hypothesis) test clearly showed the difference between the sample set and each of the listed distributions could not be explained by randomness....so statistically we must assume they are different. That's a lot of words to simply say, the data does not match any of the tested distributions.
Analysis of Sample Set Two
Data Set: DaveB-3
The SQL statement comes from a production OLTP intense Oracle system. Over the 60 second sample period, the SQL statement was executed only 81 times, hence we have only 81 samples. Numerically, the average inter-arrival time was 705.0 ms, median 149.0 ms, standard deviation 1172.1 ms, with a minimum value of 3.67 ms and a maximum value of 5649.2 ms. Again, massive variance! Notice that once again the median is less than half of the mean. The inter-arrival time is more likely to be around 149 ms than 705 ms.
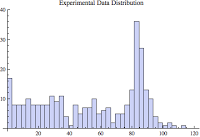
Because the data is so massively dispersed, just as with the previous sample set, I only show the lower 95% of the sample data. This means, the histogram contains 77 samples, not the full 81. This allows us to focus in on the bulk of the data and the ever-interesting (perhaps important) far left histogram bars.
Does this inter-arrival sample set conform to the normal, poisson, exponential, or log normal distribution? Visually it looks like perhaps we found either an exponential or log normal match! Sorry...our hunch is incorrect. The statistical fitness (hypothesis) test clearly showed the differences between the sample set and each of the listed distributions could not be explained by just randomness....so statistically we must assume they are different. That's a lot of words to simply say, the data does not match any of the tested distributions. Bummer. Oh well... on to the third sample set.
Analysis of Sample Set Three
Data Set: DaveB-dw1
The SQL statement comes from a production data warehouse Oracle system. Over the 60 second sample period, the SQL statement was executed 33974 times...yes this is correct. So we have lots of samples! Numerically, the average inter-arrival time was 1.76 ms, median 0.35 ms, standard deviation 17.79 ms, with a minimum value of 0.093 ms and a maximum value of 2859.76 ms. Again, massive variance! Notice that once again the median is less than half of the mean. The inter-arrival time is more likely to be around 0.35 ms than 1.76 ms.
Below are five small histogram composed of various percentages of the data. Notice that as the largest values are excluded, we get an interesting glimpse of the majority of the samples. The just below histogram shows 100% of the data whereas the bottom histogram shows the 85% of the data, the 85% of the smallest values.
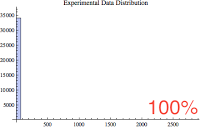
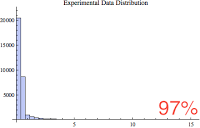
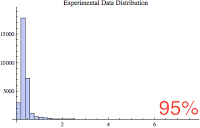
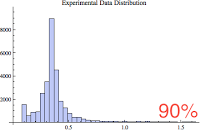
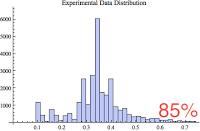
If you're like me, you're wondering if the 85% histogram confirms to one of our common statistical distributions; perhaps normal? So once again, I performed a goodness of fit hypothesis test comparing the lowest 85% of the sample data values to the normal, poisson, exponential, and log normal distributions. Yet again, they all "failed" the test, which means they are statistically so different, randomness can not account for the difference. Bummer...
Predicting the Median Values
As I was performing the analysis, I noticed that the assuming the sample data is log normal distributed, which it is not, the predicted median value was kind of close to the actual median value. So I thought I would document this to force a more realistic look at the situation. Below is the actual results from our three data sets.
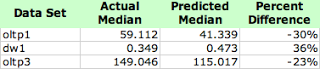
What conclusions can be draw? None...we only have three sample sets. So while I remain hopeful we can reliably predict the median, I simply do not have enough data sets to responsibly act on that hope. So.... please send me your data sets. If I receive enough I will be able to do a solid statistical analysis and post the results.
Conclusions
It is what it is... all three of our sample sets failed to statistically match the normal, exponential, poisson, or log normal distributions. Certainly this is not the results I would have liked to see. But even so, we can draw some useful conclusions, that you can check for yourself. (In fact, if you send me your experimental data, I will run it though my analysis and email you back the results.)
Don't be fooled. The Oracle SQL statement inter-arrival rates did not statistically conform to the normal, exponential, poisson, or log normal distributions. If someone claims otherwise, ask for the experimental data.
Academically interesting. The median was always less than half the mean. If you find the average inter-arrival time is 1ms, I would feel comfortable going with the assumption the median is at least half of the mean.
Strange data can be real data. A very small subset (less than 5%) of the samples are likely to be at least a factor of 10 larger than the mean. They may seem like outliers, but all of our sample sets show these exceptionally large inter-arrival times will occur, which means they are not an anomaly.
Always validate forecasts. All classic computing system predictive work assumes inter-arrival rates to exponentially distributed. But our data is clearly not...so while I can make predictions, we can see one reason why our predictions are not always spot on! This is just one reason why I stress in my courses (especially my Oracle Forecasting and Predictive Analysis course) the need to validate our forecasts.
Expect the unexpected, just not that often. In my mind, this is by far the most practical application of this research. Because inter-arrival times are clearly not constant and vary wildly, it should not surprise us when a non-heavily loaded system experiences an "unexpected" and perhaps brief slowdown. The slowdown may be short-lived, but it will occur just not that often...but with increasing likelihood as your system approaches the elbow of the response time curve. The way to reduce the likelihood of this slowdown occurring is to, in some way, influence your system to operate at a perhaps surprisingly low utilization for the most limited resource (e.g., CPU, IO, application object). If you're interested in this topic, I highly recommend Taleb's book, Fooled by Randomness.
Thanks for reading!
Craig.



