What's The Point?
If the average Oracle Database wait event, db file sequential read is 20ms, it is likely the typical value is something more like 5ms.
If you look at your Oracle Database system's wait event time distributions, you will see (details below) that an average Oracle Database wait event time is not likely to be the typical wait time and the distribution of wait times is not likely to be normally distributed. It is SKEWED.
So when you approach your IO team about the 20ms sequential read time they may look at you strangely and can honestly say, "When we watch the IO times, we see nothing like this." This posting takes a closer look at the typical wait event time, wait event time distributions/patterns, how YOU can determine the typical wait times (plus other statistical data), and plot a histogram... all based on a standard Statspack or AWR report. ...good stuff!
I first need to mention that many Oracle IO requests do not result in a wait event occurrence. I blogged about this in my "IO Read Wait Occurrence Mismatch - Part 2" posting back in January of 2011. So that in itself can be enough to drive a wedge between you and the IO team.
In this posting, I'm going to focus on wait event times, not why the IO subsystem response times may not match Oracle IO related wait event times. It's an interesting discussion for sure, but not the focus of this posting.
The Journey
Way back on November 20, 2010 I posted an entry entitled, The Average Challenge... Part 1 focused on why using the statistical average to describe common Oracle performance happenings can lead to a gross misunderstanding of reality. To demonstrate my point, I operating system traced (Linux: strace) server processes, the log writer, and the database writer. I created histograms based on the data collected and posted those graphics in the blog entry. In this posting, I will present below how you can do the same thing using data from v$event_histgram and from an AWR or Statspack report.
The challenge is, averages are usually reported to us and they are easy to calculate, so we tend to use them. Worse though, is when we say something like, "The average multi-block read wait time is 20ms." most people immediately assume most values are pretty close to 20ms and it's just as likely a value will be greater than the average then less than average. That is far from reality. Not even close. This means we are effectively misleading people by failing to communicate properly. And as a consultant and a teacher, it really really really bothers me when I'm not being clear or correctly understood.
All this thinking about averages led me on a fantastic quest into some very interesting and surprisingly practical study. First, I needed to gain a better understanding of statistical distributions. To document my research, I posted a blog entry entitled, Important Statistical Distributions...Really. I also spent some time investigating "average" SQL elapsed times and also SQL arrival rate patterns. The results where stunning, disappointing, and enlightening all at once! Currently, I am presenting some of the results of this research in my conference presentation, SQL Elapsed Time Analysis.
At this point in this journey, it's time to blog about wait times. Not a specific wait event, but the actual wait times and how to describe what's actually occurring. Knowing that saying the average wait time is Xms can be seriously misunderstood, the practicality of this is huge. I am no longer satisfied in speaking about averages. We need to get a much better understanding of what the typical value is and understand the wait time pattern (i.e., distribution).
That's exactly what this blog entry is all about; understanding Oracle Database wait time patterns, how to get good data, understanding the data, how to numerically and visually accurately show the data, and how to better communicate what the data actually means.
The Data Source
Oracle does a us a big favor by capturing wait event times and placing them into buckets or bins of a specific time range. For example, there are bins from 0ms to 1ms and from >1ms to 2ms, from >2ms to 4ms, and on up in powers of two. The good news is the data is being automatically captured, but the bad news is:
1. The bin size can be quite large. For example, a bin size of >8ms to 16ms. That's a bin size of 8ms! Plus much of the really interesting times center around 10ms.
2. The bin sizes change, that is, they increase in powers of two. This makes visualizing the distribution (think: histogram) of the wait times extremely difficult for us humans. That's why I created a tool to help us accurately visualize the data... more below.
For every wait event, Oracle stores the wait event occurrence in the 10g performance view v$event_histogram. The view is very straightforward here are a couple of links (swhist.sql and swhistx.sql) to tools in my OSM Toolkit that pull directly from this view. In addition to directly pulling from the source v$event_histogram view, more recent Statspack and AWR reports provide this information in varying levels of completeness. The formatting is a little bizarre, but with a little practice you can grab the histogram bin values necessary to create the statistics and the histogram we need.

Figure 1 above is an example of v$event_histogram data for the wait event, cursor: pin S wait on X. (my ref: 20110425_0800_0900.html) If you look at the top part of the Figure 1 you'll notice the average wait time is 5,111ms, which is 5.111 seconds! So what is the typical value and what does the distribution look like? To answer these questions, I created a Mathematica based tool that uses the bin inputs from v$event_histogram, Statspack, or an AWR report. How to get the tool and use the tool is explained next.
Finding the Typical Value and Plotting the Histogram
I created a nice little tool called, OraPub's Wait Event Time Distribution Analysis Tool which can be downloaded and used for free
HERE. The interface is not as clean as I'd like, but to make the tool freely available without you having to license Mathematica, this is what I had to do.
Retrieving the Data from the AWR report
The AWR event histogram data is provided in percentages. For example, if you look closely at Figure 1, you'll see that 6.4% of the wait event occurrences for the cursor: pin S wait on X were between 8ms and <= 16ms. It's a little strange the first few times you retrieve the wait time data, but you'll get the hang of it. For the event, cursor: pin S wait on X in Figure 1, the bin data is as follows (0ms to <=1ms, 1ms to <=2ms, 2ms <=4ms, ..., 4096ms to <=8192): 0, 0, 0, 0, 6.4, 19.4, 7.9, 3.7, 5.9, 8.1, 3.2, 1.1, 2.3, 5.0, 33.7, and 3.3. Remember that these values are percentages and should add up to 100, that is, 100%. The situation shown in Figure 1 is indeed an unusual distribution of values. Most wait event occurrences tend to be heavy near the beginning (e.g., 1ms) and extremely light at the end (e.g., 8sec).
Using the Analysis Tool
Data Entry
Figure 2 below shows most of the data entry area expanded along with the data entered. This version of my tool doesn't provide entry for the final 3.3% of the wait occurrences, which are wait times between 8192ms and <= 16384ms.
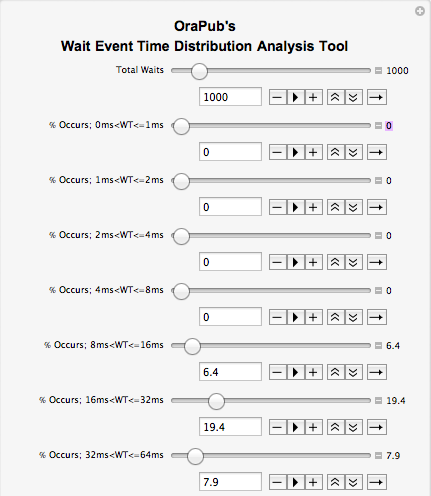
Figure 2 above shows the upper portion of the data entry area of the tool. Rather than using the slider bar, data entry is much easier if you click the "+" sign for all the entries areas and then actually type in the values. Every time you press the "tab" key the tool will recalculate, so try to avoid this. For the Total Waits entry, start with 100 and then go to 500 or 1000 for the final graphs. Do NOT enter the actual number of waits that occurred as this will take too long to render the histograms. Plus once you get over a couple hundreds samples, the results will be basically the same.
Statistical Output
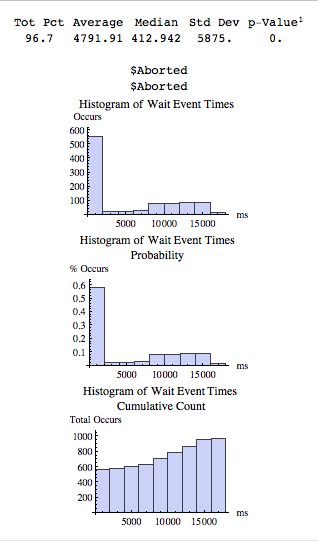
Figure 3 above shows some key statistics (e.g., median) and three of the five possible histograms. The first two histograms did not render. The first $Aborted histogram has the bin size set to 1ms and it was not possible to show over 8000 histogram bars! The second $Aborted histogram has the bin size set to 2ms and again, it was not possible to show over 5000 histogram bars.
Let's look at the resulting statistics. Figure 3 shows the following statistics:
Tot Pct is the total percentage of wait time entered. You may recall the tool did not have a data entry field of wait times between 8 and 16 seconds, which in this case was 3.3% of the values. Since the wait event percentages we entered adds up about 97%, it appears we entered the data correctly.
Average is the statistical mean. This should be close to the average wait time reported in the AWR report. The AWR reports shows the average wait time is 5111ms and the data I entered combined with the limitation in bin details, the tool determined the average was 4792ms. That's a 6% difference. Considering the crazy event time dispersion, that doesn't bother me.
Median is the statistical median, which when there is a single mode (i.e., histogram peak), is usually the typical value. The value is 413ms, which is over 4 seconds less then than the average! Wow, what a difference and this is why taking the time to do this can be very worthwhile! I will write more about this below.
Std Dev is the standard deviation. This is gives us an idea of the data dispersion, but when the data is not normally distributed (think: bell curve), which this data set not, this can be very valuable in communicating the data value dispersion.
p-Value is the statistical p-Value comparing the data with a normal distribution. Basically, if the p-Value is greater than 0.05 then the data is likely normally distributed (think: bell curve). I have yet to see wait event times be normally distributed. It's no surprise then, even at 5 decimal places (which you can't tell from the display), the p-Value rounds to zero.
The Histograms
Figure 3 above also shows the resulting histograms. Usually, five histograms will plot. The first three are standard histograms, but with different bin sizes. The first and second, which aborted, I set bin sizes of 1ms and 2ms respectively. Usually, it is useful to see the distribution at this level of detail. Usually, the wait event times are relatively short and I want to see the details at the short duration times, hence my setting the bin sizes to 1ms and 2ms. However, in this case the interesting times are much larger than one or two milliseconds. The third histogram Mathematica automatically sets the bin size. Usually all three histograms are created.
The fourth histogram is a Probability Histogram. In Figure 3, the Probability Histogram tells us that about 60% of the values occurred within the first bin, which is between 0ms and <= 1,667ms (5000ms/3 bars), that is between 0 and <= 1.7 second.
The fifth histogram is the Cumulative Count Histogram. This is just another way to get an understanding of how the data is distributed; based on the number of wait occurrences, not the percentage.
Analysis of Our Data
Now let's use the tool to learn something interesting, and yes useful, about the cursor: pin S wait on X wait times. First, notice the mean and median are very different. This is typical. It is common for the median (usually the "typical value") to be less than half of the average. In this case it is a factor of 10. The average is around 5 seconds and the typical value is around 1/2 second... a massive difference.
This is important: Notice that the AWR report (shown in Figure 1) and the subsequent data entered into the tool (not shown in Figure 2) shows that 33.7% of the wait time occurrences are between 8 and 16 seconds. In our minds, it is common to think there is a massive buildup around 8 to 16 seconds. But there is not! We need to remember that 33.7% of the wait occurrences are spread, that is dispersed, over 8 seconds! Not 1ms, 2ms, or 4ms as with near the left portion of the histogram. This is why it is so important to SEE the data in a histogram. And the difference between the mean and median also helps accentuate this.
Sixty percent of the wait occurrences occur within 1ms. That's pretty good. However, what is disturbing is if the wait does not stop at 1ms, it can end up lasting over 2 seconds. This indicates there is a problem because the way Oracle latches and mutexes are designed to work is for most of the sleeps (that is what mutex/latch wait time is, "sleep" time) to quickly reduce as the wait time increases. I don't want to get into Oracle serialization and mutex internals, but I will say this is a problem that should not be ignored. (I realize that was a gross understatement.)
To summarize, instead of saying, "The average wait time is about 5 seconds and we need to look into this." which horribly simplifies the complexity of the situation, we could say something like this: While CPU consumption and single block buffer IO reads must first be addressed, there is an unusual and potentially significant issue regarding library cache serialization. If it weren't troubling enough the average wait time is around 5 seconds, typically 60% of the time the waits are less than 1ms, yet if the wait is not satisfied within 1ms, the wait time can easily be between 8 to 16 seconds. This intense "get it now or never" situation can result in an extremely volatile performance situation and could be the result of an Oracle mutex bug..." Oh yeah... I would also show the standard histogram as well. (That's the first histogram shown in Figure 3.)
In Summary
This is just one example where Oracle wait event times are not normally distributed and therefore speaking in terms of "average" miscommunicates what is really occurring. When you need to have a deeper understanding of the timing situation and visually see the situation, you can use v$event_histogram data combined with OraPub's Wait Event Time Distribution Analysis Tool.
If you really want to apply this topic in your daily Oracle Database performance tuning work, you should watch my on-line video seminar, Using Skewed Performance Data To Your Advantage. You will not be disappointed.
Have fun and all the best in your Oracle performance endeavors!
Craig.