The Situation
Suppose you want to check if a specific Oracle Database block is an index root block. Why? Here are two very real situations.
You notice a specific block is very active and want to know if it's an index root block. Even more common is, perhaps there is a very active Oracle Database cache buffer chain latch related to a specific block/buffer and you want to know if this hot buffer is an index root block. Besides these very real examples, it's also an interesting journey into Oracle internals!
Folklore States...
Some very respectable blogs and a simple test I ran indicate an index root block is the block after it's segment header block.
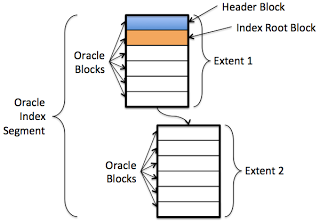
Figure 1 is a diagram of an Oracle index segment. If it wasn't for the index root block, Figure 1 would be a good diagram for any Oracle segment. The light blue colored block is the segment header block. Notice the orange colored index root block follows the segment header bock.
As mentioned above, folklore says if the segment is indeed an index, then the orange block will be the index root block. And not just now, but for the life of the index! Wow... This is a pretty strong statement and one that needs to be tested. So that's what I did and what this posting is all about.
It's Kind of Complicated
We need to determine if the Oracle Database block following an index segment header block is the index root block... for always and forever until the index is dropped. First, just dump the index and locate the root block's data block address (DBA). Second, get the Data Block Address (DBA) for the block following the index segment header block. And finally, compare them. If they match, then we have shown a situation where the block following the index segment header block is indeed the index root block. So let's do that.
Once we get the object_id from dba_segments, here's how to dump an index:
alter session set events 'immediate trace name treedump level :ObjectId';
And here's a snippet of the trace file from near the top.
...
----- begin tree dump
branch: 0x4c5461 5002337 (0: nrow: 8, level: 2)
branch: 0x4c575e 5003102 (-1: nrow: 141, level: 1)
leaf: 0x4c5462 5002338 (-1: nrow: 96 rrow: 96)
leaf: 0x4c63b7 5006263 (0: nrow: 78 rrow: 78)
...
leaf: 0x4c554d 5002573 (139: nrow: 100 rrow: 100)
branch: 0x4c63c7 5006279 (0: nrow: 213, level: 1)
leaf: 0x4c629d 5005981 (-1: nrow: 88 rrow: 88)
leaf: 0x4c554e 5002574 (0: nrow: 60 rrow: 60)
leaf: 0x4c62a0 5005984 (1: nrow: 54 rrow: 54)
...
The first/top mentioned "branch" block is the index's root block. In this case, the index root block has a data block address (DBA) of 5002337. Now let's get the data block address for the block after the index's segment header block. But first we need to get the file number and block number of the index segment header block.
SQL> select header_file, header_block
2 from dba_segments
3 where segment_name = 'CH_6_IRB_I';
HEADER_FILE HEADER_BLOCK
----------- ------------
1 808032
Now let's get the data block address (DBA) for the block just following the header block. We must remember to add one to the header block number, so the block number we are interested in is 808033.
SQL> select dbms_utility.make_data_block_address(1,808033) from dual;
DBMS_UTILITY.MAKE_DATA_BLOCK_ADDRESS(1,808033)
----------------------------------------------
5002337
Do you see it? The DBA just above (with the header block + 1) matches the first/top "branch" block's DBA (5002337) from the index trace file! So now we know how to check if the block following the index's segment header block is truly the index root block.
Now the question becomes, does it always remain this way? For example, what if create the table, create the index, and then insert rows into the table? Or what if we create the table, then insert rows, and finally create the index? If that's not enough, how about this: What if the index grows and splits? Or how about if we delete all the table's rows, insert rows until the index splits? Or how about if it we truncate the related table? As you can see, there are an infinite number of possibilities and there is no way we can test all of them.
The Experimental Setup
You can download the two experimental scripts HERE.
I created a number of tests that could be repeatedly run and easily modified and extended. There are two related scripts. The driving script is a SQL script called, doRbExpr.sql and takes a single argument, called the prefix. This prefix is the begining name of all the objects the script creates. This allows you to quickly and easily re-run the script without first removing all the objects from the previous run. The second script, getIdxRtBlk.sql, retrieves the index root block's DBA from both the data dictionary and by dumping the index, and then nicely displays them so you can easily see if there is a difference. I also show the index depth (blevel) as an added test to help ensure I'm looking at the current statistics.
The Experimental Results
Click here to see the results. As you can see, in every case the DBA of the index segment header block plus one, matches the index trace file's root block. I have rerun this test many times, and the results are always the same.
What Does This Prove?
Actually the experiments prove very little, yet they yield a tremendous value. The experiments clearly and repeatedly demonstrate that I have NOT found a way to disprove an Oracle Database index root block is the block immediately following its segment header block. All it would take is just one of my experiments to break the "block after" rule... but I could not break the rule! If you can devise a situation to break the rule, please let me know and I'll post it.
So next time you need to check if a particular block is an index root block, simply get it's segment header file and block number, add one to the block number, and compare. In my opinion, that's much easier and faster than dumping the index, parsing it, etc.
Thanks for reading!
Craig.



