Could Someone Please Quantify, "Bad"...
It seems like everywhere I turn someone says, "You don't want to hard parse in an Oracle Database. It's bad." But why? And how much "bad"? And what can I do about it? That's what I want to turn my attention to in the next few postings. This will lead us down the path to some very interesting Oracle Database performance topics; including issues relating to hundreds or thousands of child cursors, mutexes, etc. So it should be exciting!
Visualizing the Library Cache (LC)
Before we look at the experimental evidence (you know there's got to be some in this posting), we need to review just what occurs during parsing. While there are many ways to abstract and explain parsing, in summary: parsing takes raw text and makes it ready to be shared and executed. Wow, that is a massive summary for sure!

Cool picture, eh? This is a highly abstracted view of the library cache. Cursors are in blue, child cursors in read, and in the two massive clusters are the tables are white, which are being referrenced/shared by many child cursors. If you want to see more visual pictures of the library cache, check out my January, 2011 posting entitled, Library Cache Visualization Tool: How To. It's also great introduction to the LC. Plus the tool I use to create the jaw-dropping visualizations is freely available on my web-site.
Hashing to Find Something
Key to understanding parsing is to understand the Oracle LC search structure/method. Regardless of whether latches, mutexes, or both are used, Oracle uses a hashing structure to find things in the LC; cursors, child cursors, tables, sequences, views, packages, etc. If you do a search for "hash" on my blog, you'll see a number of references.
Essentially, hashing can be an extremely fast way to find something. Picture the traditional library and how you find a book using the card catalog and you have a very good conceptual view of Oracle's LC. Also, if you understand Oracle's buffer cache, cache buffer chain structure you have a good conceptual view of Oracle's LC. For a wonderful and relatively short explanation of LC hashing, look in the "It's Searched" section in my January 2011 posting entitled, Library Cache Visualization Tool: How To.

Above is a abstracted visualization of the library cache with the focus on the searching, hence the hashing structure. Here's a quick summary of how the searching works. Suppose a server process wants to know if "select status from employee" is already in the library cache. As I mention below, if the cursor is not found in the server process's session cursor cache, the SQL text will be hashed to one of the far left green "LC xB" (library cache chain number x beginning), the appropriate serialization structure retrieved (think: latch or mutex), and then the associated chain is searched until the cursor is found or the end of the chain is reached (think: "LC xE" is reached). So if we are looking for "CSR 2" will be hashed to LC chain "LC 1B" and then look for "CSR 2" on this chain. Once we hit "CSR 2" we have location information about the cursor and then its child cursor(s). But this posting is about the impact of hard parsing, so let's move on...
Parsing at Various Levels of Intensity
From a performance perspective, I tend to focus on these steps:
No parse. There is actually a "no parse." I have not actually tested this, so I'll say nothing more about it. (I feel another blog posting...)
Softer parse. Question: Does the statement exist in my session cache cursor memory? If so, where is the cursor in the library cache? (i.e., What's the address?) This does not require a LC latch or mutex because the server process's private memory is being accessed, not the shared LC searching (i.e., hashing) structure. If not, then continue to Soft Parse.
Soft parse. Question: Does the statement already exist in the library cache? If so, where is it? This requires LC latch and/or mutex access. If not, continue to Hard parse.
Hard parse. No questions, just get to it! But there are more steps involved. Allocate shared pool memory (requires shared pool sub-pool latch(es), create the cursor parent/child (requires mutex and/or LC latch), bring needed information into the shared pool (think: recursive SQL) (requires mutex and/or LC latches), and create all the associated memory links (requires mutex and/or LC latches). Wow, that's a lot of stuff and massive serialization control.
One would think that hard parsing would require significantly more resources and control than soft and softer parsing. But how much "significantly more" and is this a true performance impact, and does the impact change as concurrency increases? I am going to save the "as concurrency increases" for the next posting. It's time to look at some experimental evidence, so read on...
Experimental Setup
In summary, I gathered parse time when a statement is repeatedly executed. The first execution is clearly a hard parse and the subsequent parses will either be soft or softer. By comparing their parse times, I can tell the difference between hard and soft(er) parsing.
While the experimental setup may seem simple, it's rarely like that... In fact, since I'm going to be doing considerable research related to parsing over the next few months (and will be speaking about this in my to-be-announced one day Performance Research Seminar), I took extra time to develop a nice process and facility to gather the experimental data. Kinda like when real scientists look for dark matter... a little less intense I guess.
I originally gathered the parse times from v$sess_time_model. But I was not convinced the view of data was fresh enough. I use v$sys_time_model a lot when gathering session and system CPU consumption, but I'm usually either looking at the system over multiple minutes and not focusing only on just parse time. Because the parse time is relatively small (perhaps micro seconds), I'm looking at a specific session for a single SQL statement, and I'm not confident the view data is current, I opted to trace the session. But that meant I had more work to do. Because I want to easily repeat the experiment and use this setup in the future, I created the tools to determine the session's trace file, get the trace file, parse out the parse time, and log it.
There is much I could say about this process and the associated tools, but I won't. If you want to look at the experimental details, here are links to the various scripts.
You can download all experimental the files (notes, code snippets, driving shell script, perl script to parse Oracle trace file, ...everything)
HERE.
The experimental hardware and software is as follows: Oracle 11.2.0.1.0 Enterprise Edition running on (uname -a): Linux sixcore 2.6.32-300.3.1.el6uek.x86_64 #1 SMP Fri Dec 9 18:57:35 EST 2011 x86_64 x86_64 x86_64 GNU/Linux.
But designing and creating the experiment was not that easy or simple...
Experimental Design Challenges
This happens every time! I think I've narrowed the experimental scope down to something achievable and simple... but then once I get into it, all sorts of questions and issues come up. And these issues have to be addressed or the experiment really won't mean anything or worse mislead me and you. But the good news is, these challenges always enlighten me and force me to deal with difficult issues from a statistical, experimental, coding, and Oracle internals perspective.
I will mention a few interesting challenges I had to overcome.
- SQL statement must contain a decent amount of text. Part of the soft parse is creating a hash value based, in part at least, on the actual SQL text. I wanted something a little more realistic, so I created 1000+ character long SQL statements.
- SQL must reference a multiple objects. Again, "select * from dual" just wouldn't cut it, so I created over 50 tables, each two indexes, and used them in the SQL. Again, I wanted to ensure some realistic soft parsing occurred.
- SQL statement must be unique to insure a hard parse. I had to create textually unique SQL or a soft parse would occur when I wanted a hard parse.
- SQL statements must be similar to compare fairly. If I made the SQL very different, then I couldn't gather a bunch of samples to get a fair comparison. My solution was to use the same SQL except for bind filtering and table name. But the tables are exactly the same and contain no rows. As you'll from the results, the times from one SQL statement to the next are very similar.
- Flushing the shared pool. One way to ensure a hard parse is to flush the shared pool. However, the next statement forces Oracle to bring in all sorts of optimization information, like histograms, etc. I think much of this information is used for both my SQL and other SQL. (This is easily seen as the resulting trace file includes lots of recursive SQL.) I felt this was not a fare test because in real production systems the hard parse issue is not focused on after flushing the shared pool, but during normal production operation. So I did not flush the shared pool, but relied on unique (but similar) SQL statements to ensure a hard parse.
- Gathering only the parse time. I couldn't simply gather the time before and after the SQL statement ran (i.e., elapsed time). I needed a specific component of the statement's elapsed time; the parse time. To do this I had two basic options; use the parse time columns from v$sess_time_model or SQL trace and grab from the trace file the parse time for the specific statement. For reasons I mentioned above, I opted for the trace file approach.
- Parse time; CPU and/or/versus elapsed. Keeping in mind from an Oracle perspective a server process is either consuming CPU or waiting, I'm interested in both. As you'll see from the experimental results in this posting (and the next post when I crank up the concurrency), the results are intriguing.
- Concurrency (i.e., competing load). The experiment in this posting is really a test of Oracle's parsing speed in a best case scenario, which is basically a single user system. That's nice because concurrency brings variance and is messy. But concurrency is also reality. So while the experiment in this posting is single user system, the next will contain the results based on various levels of concurrency and load.
It's questions like these that cause what appeared to be a simple experiment into a multi-day ordeal. It's not easy or simple to create good experiments that mean something.
Experimental Results
The raw experimental data is available as raw insert statements or the SQL selected data after the inserts where completed. But a much more interesting and enlightening view requires some statistics and visualization.

[Note: All but the "Elapsed time P-Value" columns should be familiar. A P-value greater than 0.025 indicates the sample set is likely to be normally distributed. For this blog posting, it's not important.]
Clearly the first execution, which is a hard parse, takes much longer than subsequent executions. In fact, the second execution is around 180 times faster than the first execution and the third execution is around 860 times faster than the initial execution. That is a massive difference!
So now when some says that hard parsing is expensive, you can confidently add:
Craig's no-load test showed the second (soft parse) execution was over 180 times faster than the first (hard parse) execution.
But we can say more! Supposedly (i.e., I don't know the source) the softer (not soft but softer) parse kicks in after a session has run the same cursor three times. This means we can't expect an additional parse time reduction until the fourth execution. If you look closely at the above data, you'll notice the fourth, fifth, six, and seventh (which is the last test) execution are all within 1100 to 1200 times faster than the initial execution.
Craig's no-load test showed softer parsing was over 1100 times faster than hard parsing!
In fact, statistically there is no difference between the fourth through the seventh executions. So now you can also confidently state that:
Craig's no-load test showed once a statement is executed four times, the parsing time is no longer significantly reduced. This is, at least in part, a demonstration of Oracle's session cache cursor facility.
That's good stuff!
How the Results Substantiate these Claims
If you're wondering why I can state there is or is not a significant difference between execution X and Y, it's because I ran a statistical significance test for every execution sample set combination, which is results in a 7 by 7 matrix. This matrix is shown below. In each cell is the test's P-value.
Because all but the first (hard parse) sample sets are not normally distributed, I used what's called a location test to determine the P-value. I took a P-value less than 0.025 as meaning the sample sets are truly different. For more details about this plus other statistical and visual goodies, download my Mathematica Notepad in either PDF or native format. I also provide P-value information in my previous blog entries: Consider doing a search for "p-value".

Here's how to interpret the above matrix. If a P-value is greater than 0.025 then it's likely the two sample sets came from the same population. This is more correct way of saying, there is no real difference between them. If a P-value is less than 0.025 then it's likely the two samples did NOT come from the same population. This is a more correct way of saying, their difference can not be explained by the random picking which caused our sample sets to appear similar. It's more than that... they are different! (This is of course, a non statistician way of explaining this.)
For example, when compare sample set 1 to sample set 1 (yes, itself), the P-value is greater than 0.025 and therefore they likely came from the same population. Dah... Now compare sample set three to sample set four through seven: The third execution, row 3, columns 4 to 7. Notice the P-values are all less than 0.025, actually 0! This means the sample set values are significantly different. But there's more!
Notice when comparing the P-values for sample sets four through seven to each other (i.e., 4 to 5, 5 to 7, etc.), their P-values are always greater than 0.025. This means while there is a numeric difference, statistically the difference is not significant! This is why I could state above, "After four executions, parse times are no longer significantly reduced." Cool stuff!
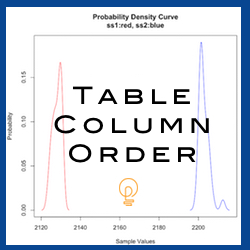
I like pictures. And below is a smooth histogram showing the difference between the third to the seventh execution.

If you feel the difference between the third execution and the fourth or fifth execution is not significant, remember to check the statistical significance test P-values shown in the above matrix.
Summary
There is a lot to take away from this posting. First and foremost, it's very clear that an initial SQL parse, that is the hard parse, takes many times longer than subsequent parses. My non-load test showed the second parse (soft parse) was 180 times longer than the initial (hard) parse! Second, once session cache cursors kick in after the third parse, parse time drop over 1100 times when compared to the initial hard parse!
Reality perspective: I need to mention that even though hard parsing is clearly much more resource intensive and takes much longer than soft and softer parsing, if a statement takes multiple seconds to run, it's a valid question to ask, "Who cares?!" I mean, do we really care if parsing takes 23 ms compared to 0.023 ms if the statement elapsed time is 10 seconds? Perhaps if concurrency stretches these numbers, but otherwise perhaps not. The true answer is to analyze performance to see if hard parsing is impacting performance.
Keep in mind my testing was performed on a no-load system. This is not a bad thing, but by design. I wanted a brut-force non-concurrency code algorithm test without the distraction of serious resource competition.
In my next posting, I'll perform the same tests but with different levels of concurrency intensity. Can't wait to share the results!
Thanks for reading!
Craig.