When I teach, I often do wacky things; like role play being a server process or a memory structure. But if there is one thing that guarantees to bring everyone to a state of silent anticipation is when I say, "The reported operating system run queue includes both processes waiting to be serviced and those currently being serviced." Everyone will stare straight at me, waiting for me to say I was just joking. But I'm not joking and it's the truth.
Ask ten Oracle Database Administrators (DBAs) what the OS run queue is and nine of them will tell you it's the number of processes ready and waiting for CPU. After all, that's what we've been told and the OS manual pages seem vague enough not to contradict this. When I created the HoriZone product (OraPub's now defunct capacity planning product) and was writing my Oracle Performance Firefighting book, I had to verify this; so this became a pretty serious endeavor for me. In this blog entry, I'm going to drill down into what the OS reported run queue is and demonstrate that what most of us have been taught is simply not true.
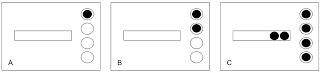
Looking at the above diagrams, there are three key parts:
An outlined circle represents a CPU core. Diagrams "A", "B", and "C" each have four CPU cores. This could represent a single quad-core CPU, two dual-core CPUs, or four single-core CPUs. The reason cores are used is because they scale well, whereas threads do not. On the flip side, using actual CPUs will understate the CPU subsystem's power and not reflect the actual queuing situation as well. I'll blog about this at a latter time, but this is a well documented and the accepted capacity planning perspective.
A solid circle represents an OS process; either waiting or being serviced by a CPU core. In diagram "A" above, there is one process in the system, in diagram "B" there are two, and in diagram "C" there are six processes.
A rectangle is the single CPU run queue where all processes must pass and possibly wait before being served by one of the CPU cores. In diagrams "A" and "B" there are no processes in the run queue and in diagram "C" there are two processes in the run queue.
The Shocking Reality
OK, let's put some surprising reality into this. Based on upon the description of the above diagrams, diagram "A" and "B" have no processes in the run queue, whereas diagram "C" has two processes in the run queue. However, the standard performance reporting tools sar, vmstat, and top will show the CPU run queue for diagram "A" as one, in diagram "B" as two, and in diagram "C" as six. Really.
If you're like most DBAs at this point, you're giving me a strange look and waiting for what I have to say next because I've just poked a hole in something you (and me too) have believed to be true for perhaps twenty years of your life. And of course you want some proof... and this is what the rest of this blog entry is...proof. Proof as best I can supply in four forms; manual pages, a software vendor's perspective, my performance firefighting experience, and a simple experiment you can run on one of your idle Unix-like machines that will show without a doubt that the OS reported CPU run queue counts both processes ready and waiting for CPU and also processes currently receiving CPU resources.
Check the man pages
The first thing I did was to check the sar manual page (linux, solaris, aix, hpux) looking for the -q option (the average CPU run queue) with a column heading of runq-sz. This is what I found:
Linux: run queue of processes in memory and runnable.
Solaris: Run queue length (number of processes waiting for run time).
AIX: Reports the average number of kernel threads in the run queue.
HPUX: Average length of the run queue(s) of processes (in memory and runnable)
That obviously doesn't do much to clear things up. In fact, it brings more confusion than anything else.
Contact a forecasting software product company
My next data point was to contact a software company that creates predictive analysis software. Any forecasting product company will have to deal with the reality of gathering OS performance statistics and then correctly interpreting them and integrating them from both a queuing theory and a reality perspective. So I figured they would really, really know the true situation. (I had to do the same thing when I created my now defunct HoriZone predictive analysis product a few years ago.)
There is a UK based company that produces a wonderful forecasting product. In the past Metron has sent some of their employees to my Oracle Forecasting & Predictive Analysis training course so I figured I'd be more likely to get a response from them.
So I emailed their support staff and the next day I received an email from Colin Woodford that included, The run-queue length means "the sum of the number of processes that are currently running plus the number that are waiting (queued) to run." Hum... so far that was the most explicit response I have received.
My personal experiences
Working on big and mean Oracle production systems for the past twenty years has repeatedly shown that when the OS reported average CPU run queue nears the number of CPU cores, users will start calling and complaining of poor system responsiveness. I also noticed that the average CPU utilization is usually between 80% to 95%, depending on the number of CPU cores.
While this is a topic for another blog entry (or two), I've also noticed that for snappy OLTP performance the run queue needs to be clearly below the number of CPU cores but to minimize the duration of a CPU intensive batch process, the CPU run queue will be just over the number of CPU cores.
Run a straightforward and repeatable experiment
I love to design and run experiments. If you have read my papers and my books you'll notice they are full of experiments. In my earlier Oracle days I spent a lot of time learning how to design a good experiment, which includes isolating the area of interest, running it many times to get a good statistical sample size, how to process the statistics, and how to correctly interpret the results. Sometimes the experiment will take less than an hour to run, but some experiments (like the one I'm going to present) took many days to run!
The stronger and more controversial the statement I'm making the more experimental detail I will provide. From an author's perspective, it's a difficult balance to determine how much detail to supply because some people want all the details while others just want the answer. The other tangle is computer configurations can be slightly different, so many experiments will not exhibit the same result even if the load placed on the system is the same. But for this experiment, we are fortunate in that if you have an idle machine sitting around, you can run the exact same experiment and should see the exact same results.
For this experiment, I used a Dell machine with a single four-core Intel 2.6GHz CPU running Oracle Unbreakable Linux 2.6.18-164.el5PAE. Oracle software is not involved in this experiment. This information was gathered using the uname -a and the cat /proc/cpuinfo commands.
The key to this experiment is I created a very simple yet very CPU intensive process using the bc command. So intensive is this process, it essentially consumes 100% of an entire CPU core. So for example, when one of the load processes is running (and nothing else), the four-core CPU subsystem will show 25% utilization. When there are two of the CPU intensive processes running, the four-core CPU subsystem will show 50% utilization. When you see this type of behavior, you know you'll dealing with a full-on CPU sucking process!
For every incremental load increase, I gathered 32, 15 minute (900 seconds) duration samples. The system was loaded starting with one CPU intensive process on up to ten. So for the complete experiment I gathered a total of 320 samples and with each taking 15 minutes, you can see why it took four days to complete. But I wanted at least 30 samples for each incremental load and I wanted more than just a few minutes duration for each sample to ensure the system had a chance to stabilize and really run at that load intensity.
I used two separate scripts for this experiment. The first script (shown below) is the runqtest.sh shell script. It is the main controlling script that incrementally starts an additional CPU intensive process and records the CPU utilization and run queue for later analysis.
The second script (also shown below), killbc.sh, will search out and kill all bc processes. Anytime I run an experiment where the system can take over the entire machine causing it to become unresponsive, I will create a kill switch type of process. It also allows me to very quickly restart the experiment, which I frequently have to do when I'm developing the experiment.
Shown below are the two scripts:
[oracle@fourcore runqueue]$ cat runqtest.sh
#!/bin/sh
maxprocs=10
calmsecs=5
samples=32
interval=900
tmpfile=/tmp/sar1.tmp
finalfile=spinresults.txt
rm -f $finalfile
echo "Showing all bc processes now."
ps -eaf|grep bc|grep -v grep|grep -v vim
echo "If you see any bc processes, quite now!"
sleep 5
for ((p=1;p<=$maxprocs;p++))
do
echo "scale=12;while(1<2){1+1.243}" | bc > /dev/null &;
sleep $calmsecs
for ((s=1;s<=$samples;s++))
do
echo -n "Starting sample now: "
echo -n "processes=$p sample=$s interval=$interval ..."
sar -uq $interval 1 > $tmpfile
echo "done"
util=`cat $tmpfile | head -4 | tail -1 | awk '{print $4+$5+$6}'`
runq=`cat $tmpfile | head -7 | tail -1 | awk '{print $3}'`
echo -e "$p\t$s\t$interval\t\t$util\t$runq" >> $finalfile
done
done
./killbc.sh >/dev/null 2>&1
echo "Complete runqueue test at `date`" >> $finalfile
echo ""
echo ""
echo -e "Procs\tSample\tInterval(s)\tUtil%\tRunQ"
cat $finalfile
You will notice the runqtest.sh script calls the killbc.sh script, so here it is also:
[oracle@fourcore runqueue]$ cat killbc.sh
ps -eaf|grep bc|grep -v vim|grep -v grep
for p in `ps -eaf|grep bc|grep -v vim|grep -v grep|awk '{print $2}'`
do
echo "killing process $p now."
kill -9 $p
done
ps -eaf|grep bc|grep -v vim|grep -v grep
Sample and Population Dispersion
The next couple of paragraphs delve into statistically describing the sample and population dispersion. If you're not interested in this, just jump down to the section entitled, Experimental Results.
To describe our samples we need some, well...samples. But if we are going to make inferences about the entire population (our samples and all the other possible samples), we need to gather 30 or more samples. Why the magical 30 samples? When describing the dispersion of our samples the [sample] standard deviation is used, but when describing the population dispersion, we should use the population standard deviation. In part it's because the only difference between the sample standard deviation and the population standard deviation is there is either an N or an N-1 in part of the denominator. Below is the formula for the sample standard deviation.
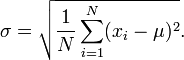
Notice the 1/N. For describing your samples (as shown above) the formula includes the 1/N. However, for describing all samples, which includes our samples and the samples we did not gather (that is, the population) the 1/N is replaced with 1/(N-1). When N reaches around 30, the difference between 1/N and 1/(N-1) becomes extremely small and insignificant. So when I want to make inferences about the entire population, I always ensure I have at least 30 samples.
If you want to run this experiment but don't want to wait four days to get the results, use a sample duration of perhaps only 1 minute. Since the load is very simple (unlike when Oracle is involved) it will stabilize very quickly. If the results fluctuate wildly, then you'll know you need to increase the sample duration time. In addition to the previous few paragraphs above, it is important to gather 30 or more samples as this will confirm your samples are not the result of randomness or anomalous behavior.
The Experimental Results
Here is my summarized experimental data:
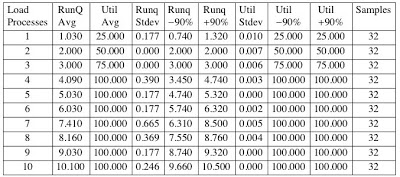
Here are the chart column definitions.
Load Processes. This is the number of CPU intensive bc processes that were running.
RunQ Avg. This is the average OS CPU run queue as reported by the sar -q command.
Util Avg. This is the average OS CPU utilization as reported by the sar -u command.
Runq Stdev. This is the standard deviation of the average run queue samples.
Runq -90%. This is the 10%-tile or the -90%-tile statistic based on the average run queue and its standard deviation. Mathematically, this is (RunQ Avg - 1.645 * standard deviation). To translate this into English, with the number of load processes at 10, the average run queue was between 9.660 and 10.500, 90% of the time.
Runq +90%. Similar to the Runq -90%, but the upper or higher end of the spectrum.
Util Stdev. This is the standard deviation of the average utilization samples.
Util -90%. This is the 10%-tile or the -90%-tile statistic based on the average utilization and its standard deviation. Mathematically, this is (Util Avg - 1.645 * standard deviation). To translate this into English, with the number of load processes at 10, the average CPU utilization was between 100.000 and 100.000, 90% of the time... yes that is extremely consistent.
Util +90%. Similar to the Util -90%, but the upper or higher end of the spectrum.
Samples. This is the number of 15 minute duration samples taken at each load increment.
Key Observations
Here are some key observations:
1. As you can see, the results are extremely consistent. This strengthens our conclusions.
2. There are four CPU cores in this Linux box. This is pretty obvious because each additional process increments the CPU utilization by 25% until, of course, we hit 100% utilization.
3. When there are one to four load processes running, the OS reported run queue matches the number of processes. This demonstrates that the Linux reported run queue does indeed include the running, that is, CPU consuming, processes. Period.
4. When the OS reported run queue surpasses the number of CPU cores while still equaling the number of load processes, this means the Linux reported run queue includes both the processes running (consuming CPU) and processes waiting to run (waiting to consume CPU but in the CPU run queue). Period.
To summarize this experiment and to make sure this is no miscommunication, this experiment demonstrates that the OS reported average CPU run queue contains both processes currently running and processes ready/waiting to run.
To Summarize
Usually I find the manual pages very helpful and enlightening, but in this case they are pretty much useless. I am very appreciative that Metron returned my email and even more so, that there definition was very specific. I hope this experiment puts to rest any doubts you may have about the definition of the OS reported CPU run queue. While I have not run this experiment on other Linux's or Unix's, I'm confident the results will be similar. For Windows systems it could be different; after all Windows is an entirely different beast.
To summarize (again), this experiment demonstrates that the OS reported average CPU run queue contains both processes currently running and processes ready/waiting to run.
Thanks for reading!
Craig.