Some background...I think what separates Oracle Database Administrators is their ability to communicate. If you take the time to study (my courses and books can help), every Oracle DBA will eventually become an Oracle Database technology expert. But from this point is where our uniqueness become more interesting as we each set out on a different career path.

To improve my teaching I spend countless hours developing stories, role-plays , and various entertaining ways to transfer very complicated topics to DBAs. But what has been frustrating for me was the lack of visualization. Pictures, white boards, and flip charts are OK, but I wanted to do something that's visually amazing, flexible, and free. Finally, I discovered that Mathematica could help me in this quest. So last year I embarked on a journey to visualize aspects of Oracle's technology.

I started with Oracle's buffer cache. Thousands of you downloaded the tool and the read the associated blog entry (its documentation). A few months ago I created an initial visualization tool for Oracle's library cache. The visualizations where jaw dropping but it was too highly abstracted for my liking, didn't relate enough with production systems, and had no associated documentation. Finally, this has changed...
Oracle's library cache (LC) is amazing. And viewing it on your PC is even more amazing and very enlightening. I just completed a significant update (still free) that is much more realistic, based on an 11g library cache dump and allows you to enter details from your real production Oracle system! Yes, it's very cool! You can download OraPub's Library Cache Visualization Tool here for free.
The purpose of this blog entry is to introduce you to the new version (2g) of OraPub's Library Cache Visualization Tool and also to introduce you (if you desire) to Oracle's library cache. I hope you enjoy this blog entry and the visualization tool!

Library Cache Introduction
Within Oracle's shared pool exists the library cache (LC). The library cache can be abstracted and viewed like a classic library's card catalog system. The cards are located by hashing to the correct catalog and then sequentially searching through the catalog looking for the desired card. Each card references a book's location and a few other details.
It's Searched
Oracle's LC is searched using a hashing algorithm. Suppose our server process is parsing the SQL statement, select * from dual. The server process attempts to minimize the time and resources required to parse the statement. One strategy employed is to check and see if the SQL statement has already been parsed and its cursor available in the library cache. But the server process must first locate the specific cursor reference, just like we must first locate a printed book's reference card.
The server process will pass the SQL statement text to a hash value generation function that will transform the text (e.g., select * from dual) into a hash value (e.g., rT4rif87ujc). The hash value is then passed to hash function which, will output a number within a specified range (e.g., 0,...,350000). The output number (e.g., 3216) is a reference to what is called a hash bucket. If our SQL statement's cursor exists in the library cache it will have a reference that is associated with this hash bucket (e.g., 3216).
Each hash bucket can have an associated chain. The chain length could be zero (which is actually the most likely on real Oracle systems) or it could be perhaps two or even three references long. The references are more properly called handles, because they reference a chunk of memory within Oracle's shared pool. Continuing my example, the server process jumps to the hash bucket (e.g., 3216) and begins sequentially scanning its associated hash chain searching for my SQL statement's hash value (e.g., rT4rif87ujc). If it finds the hash value (the cursor reference) that's a soft parse, if not, then it must create the cursor plus a bunch of other stuff...this is known as a hard parse.
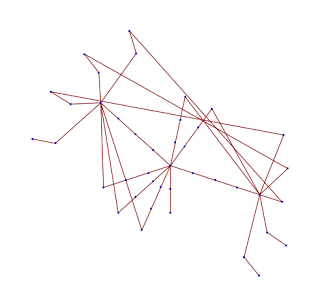
The image below is a visual example of unrealistically simplified LC hashing structure...but it serves our purpose here wonderfully.

The LC hashing structure modeled above has 16 hash chains. Most chains contain two references, that is, handles. Suppose in my quest to locate my SQL statements cursor (hash value, CSR 5), I hash to bucket, LC 3. The B is for beginning and the E represents the chain's end. My server process will now begin to sequentially search the LC hash chain LC 3 looking for my cursor, represented as CSR 5. It will quickly find it! Now my server process has access to all sorts of details related to the SQL statement and does not have to build the cursor, which is relatively expensive and part of the hard parsing process.
References and Relationships
The LC is responsible for maintaining the relationships between objects in the LC...and it's complex. This is why the visualization tool is so cool because we get a glimpse of this complexity. As a quick example, the LC will maintain the relationships between tables and SQL statements (more specifically child cursors). This way if the table is altered, Oracle knows which child cursors and cursors to invalidate. This invalidation process will propagate to associated views, procedures, functions, triggers, packages, etc. Oracle tries very hard to limit this propagation as it has some nasty repercussions (that I will not discuss here).
The LC handles point to memory that contains information about procedures, functions, tables, views, synonyms, cursors, child cursors, and I'm sure there are others. Not only are there references to these nodes, but references to other nodes. For example a parent cursor (select * from customers) can reference a child cursor (which has a specific execution plan) and a table (customers). When you add in the connections with procedures and functions it's gets pretty crazy. Or how about tables that are referenced in multiple statements or when a cursor is shared by multiple procedures, functions, or packages...
The image below is an example of the relationship between 2 cursors (parent cursors), their associated 4 child cursors, and their associated 5 tables. As you can see, with only a few objects and especially when sharing occurs, the relationships can become quite complex.

If I create a table, a couple of SQL statements, a procedure, and I force a couple of child cursors by changing the optimization mode, and finally dump the library cache to a trace file, I am able to diagram their relationships. But it takes awhile. Mapping more than a couple of objects would quickly turn into a nightmare!
The Core Objects
As I mentioned, the LC references and contains meta data about Oracle objects. Not all objects defined in Oracle's data dictionary, but only those that have been recently referenced (there are exceptions) and have some cached information. For example, you can not get a good idea about the number of tables referenced in the LC by issuing a select count(*) from all_tables.
You can get a list of all the types or namespaces currently residing in Oracle's LC by issuing this simple command:
select namespace from v$librarycache order by 1;
On my 11g system there was 17 namespaces. The parent cursors and child cursors (more below) are contained within the SQL AREA namespace. Personally, I find the LC dictionary views inadequate. For me, if I want to get an idea of what is going on in the LC, I dump it to a trace file. Here's how to do that:
alter session set max_dump_file_size=unlimited;
alter session set events 'immediate trace name library_cache level 10';
Of course the next question is, "Where the heck is my trace file?" In 10g and earlier in SQL*Plus issue a show parameter user_dump_dest. In 11g, here's one way to get the full path to the trace file.
select tracefile from v$process where addr=(select paddr from v$session where sid=(select sid from v$mystat where rownum=1));
If you look closely in the trace file you will eventually see the word FullHashValue followed by a bunch of text. Look to the right and you will see Type=. Below is an example from a recent trace file with the hash value and identifier dramatically shortened.
FullHashValue=9ba Namespace=SQL AREA(00) Type=CURSOR(00) Identifier=395 OwnerIdn=5
This object is, obviously, a cursor. If I skip down a few lines I see this:
Parent Cursor: sql_id=8zu55nbpz8fdu parent=0x3030fe60 maxchild=2 plk=n ppn=n
Notice the maxchild=2 entry. This means this cursor (i.e., parent cursor) has two child cursors. If was to jump back up a couple lines in the trace file, I would find.
Child: id='0' Table=30310d58 Reference=303103e4 Handle=3030fb9c
Child: id='1' Table=30310d58 Reference=303105b4 Handle=30303c24
These are the references to the two child cursors. Interestingly, if I search for the findme table reference in the trace file, it will have a reference section and I will see it has references to handles 3030fb9c and 30303c24. So you can see there is a link from the table to the associated child cursors.
A child cursor is required for different execution plans for the syntacally identical cursor. For example, if I run the below code, one parent cursor and two child cursors will result.
alter session set optimizer_mode=all_rows;
select * from findme;
alter session set optimizer_mode=first_rows;
select * from findme;
This is one reason why if you query from v$sql you can get more than one row returned. The situation quickly becomes complex when adding even a single procedure that references the findme table. Each procedure has a reference to the child cursor of any SQL or other procedures and functions contained within it. And all the table's referenced by the procedure's child cursors also point to the procedure itself. It can become confusing very quickly.
The Relationship Mapping
With just the simple situation outlined above, plus some details I conveniently left out, you can see:
Every child cursor references a parent cursor.
A parent cursor may reference a child cursor, but not always.
Every procedure references the child cursor of SQL, procedures, etc. it calls.
Table references point to all procedures and child cursors that reference it.
I think you can see that with just a few objects, the connections will soon look like sub-atomic particles or astronomical objects! But that's what makes this all so interesting...
For my LC visualization tool I made the decision to not include packages, procedures, functions, and triggers (and other objects). Their inclusion would have signifiantly increased the complexity of the visualization beyond being useful. If you keep in mind that what you are seeing is probably the least complex situation given the inputs then you'll be fine. Even the introduction of a few procedures will significantly increase the node connections.
Tool Introduction and Control
You can download OraPub's Library Cache Visualization Tool for free from OraPub's web-site here. As the tool's page indicates and links to, you will need to download and install Mathematica's free player. It works just like the Acrobat Reader in that the reader is free, but to create the document you must license Acrobat, which in this case means Mathematica. (Note: OraPub has a special relationship with Mathematica's company, Wolfram and can arrange for a discounted license. Just email OraPub for details.)
This posting is based on version 2g of OraPub's LC Visualization Tool. Other versions will operate similarly, but the images shown below could be somewhat different.
Note: You can always reset the visualization settings by clicking on the upper right hand plus sign and then selecting Initial Settings.
When you first run OraPub's LC Visualization Tool, it will look like this:

If you just can't wait, click on Preset and select Intro 2. Click on the image and drag your mouse to rotate the image...more on this below.
When you first run the tool, as shown above, a very simple, very unrealistic, highly abstracted, yet very useful and cool LC visualization appears along with all your control options. Here's a short description of the tool's control mechanisms:
Cursors w/Child Cursors is the number of parent cursors that have one or more child cursors.
Cursors wo/Child Cursors is the number of parent cursors that do not have a child cursor. While we typically think of parent cursors always having at least one child cursor, if you examine a library cache dump you will quickly notice this is not true. For demonstrations, I usually set this to zero.
Child Cursors is the total number of child cursors in the library cache. If you were to execute a SQL statement, dump the LC and examine the trace file, you will find your SQL statement's parent cursor and you will notice it has one child cursor. The number of child cursors be set to at least the number of Cursors w/Child Cursors. If not, the tool should automatically reset the number of child cursors equal to the number of parent cursors with children. It is common for a parent cursor to have multiple child cursors.
Unique Table/Views is the total number of unique tables and views. While there are other objects such as synonyms and sequences in the LC, for simplicity they are not represented. A real child cursor will reference at least one table, view, synonym, etc. In this tool, a child cursor will reference one or more unique table/view.
Table/View Share % is the percentage of unique tables that each child cursor will be associated with. This injects the messy pointer reality that a table will likely be associated with many child cursors. You will notice that when we increase this parameter, the number of memory references dramatically increases. For example, a customer table will likely be associated with literally hundreds of SQL statement child cursors. This tool will evenly (i.e., uniformly) distribute the tables to the child cursors. In a real Oracle system, obviously this will not occur as some tables will be referenced by more child cursors than other tables.
LC Hash Chains is the number of library cache hash chains. Each LC bucket will have a hash chain, though in production systems most chains will contain no references. At the top of an Oracle 11g LC dump, you will notice a very nice table that shows the chain length by the count of chains. You may find that most of your chains have a length of zero. For fast searches we want a chain length of only one. Hashing is a fascinating topic and is very important for Oracle memory management. This is why I gave quite a bit of space on this topic in both the buffer cache and library cache chapters in my book, Oracle Performance Firefighting. For simple demonstration purposes I usually set the number of LC hash chains to around the number of tables and child cursors. In real Oracle systems, there can easily be over 100,000 chains!
To Plot allows us to focus on only the LC chains, the other objects in the LC cache (cursors, child cursors, and tables/views), or all the objects. This is a great way to study each topic without the complexity of additional memory links. But as you'll see, when objects are fully shown the complexity can be dazzling! Parent cursors without a child cursor are only displayed with the Full option.
Scale % allows you to enter production size values for the parent cursors, etc. but only visualize a percentage of them. This is important because a meaningful visualization of a production system must be scaled down or it will take quite a long time to create a meaningless visualization. Before you enter production size values, set the Scale % to 0.1. Then increase one tenth of a percentage point at a time until the desired visualization appears. Click on the control's plus sign and then click on the just displayed plus sign to jump 1/10 percentage point. This will also convey just how massive and complex Oracle's LC is. The scaling algorithm is very crude: the result is simply the the given percentage multiplied by the given number of objects. For example, if the number of unique tables is 20000 and the scale percentage is 10%, 2000 tables will be visualized...much too many by the way.
Preset was implemented so we can quickly display some basic pre-defined visualizations. This is important: If you want to modify a preset, you must first set the Preset to Custom. If you forget to do this, your changes will immediately be overwritten by the displayed preset values.
Circle Size allows the two-demonentional (2D) visualization circle sizes to be adjusted. Based on the number of objects displayed and the viewing area, for a visually pleasing image you sometimes will want to adjust the colored circle size.
Visualization options provide you with a number of ways to view the same exact information. The Point option simply shows a single point for every node. This allows lots of information to be displayed two-dimensionally. You can mouse-over each point to see what it is. The 2D option displays each node as a circle with the node abbreviation text visible (usually visible). This is a fantastic way to learn about the LC: With all the memory object sharing and list connections, as the number of displayed items increases, the value of the two dimensional view quickly diminishes. The 3D option shows each node as a small sphere and allows you to view lots of information in a more realistic way. The spheres are color coded based on the selected Color Scheme (next item). The 3D view opens up a whole new way to study the LC. But eventually the 3D option can become cluttered and so the 3D Wire option changes the spheres to points and allows the object name to be displayed on a mouse-over (you have to be zoomed in pretty close though).
Color Scheme allows you to pick the visualization color scheme. This allow you to pick a more personally pleasing visualization. But even more important, I find that every projector/beamer projects the same color differently. By trying the various color schemes, you should be able to find one that works well. Using the default color scheme of Multi, parent cursors are blue-ish, child cursors are brown-ish, tables/views are yellow-ish, and the beginning and ending of LC hash chains are dark green.
Using the Tool - First Time
This is what you will see when you first run the tool. (It's the same image as the one shown at the very top.) If you have messed with the settings, just click on the Preset Intro 1.

Notice that each object type has a distinct color and abbreviation. By default, parent cursors are brown-ish and labeled as "CSR". Child cursors are brown-ish and labeled as "CCSR". Tables are yellow-ish and labeled as "TBL". Also notice the all the cursor and table related settings match what is being displayed.
There are two key items I want to highlight.
First is the Table/View Share % is set to zero. Notice in the above visualization no table is shared with another child cursor. Below is the result with sharing set to 100%. You can do this yourself; set the Preset to Custom and then click on the Table/View Share % 100 option. To get a good looking image, on my screen I also had to set the Circle Size to 0.15.

In the above image the tables are 100% shared. Because there are three child cursors (CCSR1,...CCSR3), each table node has three links.
The second item I would like to highlight is the LC hash chains are not shown in the above image. This is because the To Plot option is set to Objects. If I click on LC Chains, as the image below shows, only the LC chains and their contents is displayed. On my screen, I also increased the Circle Size back to 0.3.

Interestingly, as a library cache dump indicates and visualized above, the child cursors are not directly on a hash chain. However, tables referenced in a parent cursor and and the parent cursors are directly associated with a hash chain. Referencing the image above, if a change was made to table TBL 2, Oracle would end up hashing to LC chain 2 (LC 2B, the "B" is for beginning and the "E" is for ending) and start sequentially scanning looking for the handle. TBL 2 is the first entry on LC chain 2. Oracle would then invalidate the table, follow the reference from the Table 2 entry to its associated child cursors (CCSR1, CCSR2, CCSR3) and then also to the cursors (CSR 1, CSR 2, CSR3)...invalidating them all!
In a real production Oracle system, most LC chains are only one object in length. So the above image would never, we hope, actually occur. While not shown, if you increase the number of LC hash chains to a few more than the number of objects you will get a truer looking abstraction.
Displaying the LC chains and the other objects separately is a wonderful way to learn about LC structures. But we miss out on understanding the complexity. The image blow has the To Plot set to Full, thereby displaying all the objects with their associated links. For my screen also changing the Circle Size back to 0.15 looked the best.

Because there are only a few objects in this visualization we can pretty much follow all the links. But even now, it's tricky. Plus they can easily be overlapping links that are not visible from a two dimensional perspective. Changing the Orientation (located at bottom of the tool) can sometimes help when there are overlapping lines. The image below has the Visualization set to 3D plus I rotated the image and zoomed in so get a very nice image.

The objects are color coded, so with a limited number of objects we can see exactly what's going on. The green sphere's are the beginning and ending points of the LC chains. Using the default Color Scheme, Multi cursors are white-ish, child cursors are brown-ish, and tables/views are yellow-ish. For three dimensional images you may want to change the default Color Scheme.
You will notice even with thousands of nodes, Mathematica typically plots the LC chain begin and end points relatively far away from the mass of nodes. And when the number of nodes increases as well as the number of LC chains (remember most LC chains have a length of only one) the image looks like an exploding star.
Using the Tool - More Complexity
For this visualization select the Preset, Intro 2. This is a more realistic, though still highly abstracted, LC visualization. Immediately your eyes will pick up on a number of things.

With more LC chains their beginning and end points look like pins in a pin cushion! Having many short LC chains enable very fast searches. The dense center is due to intense table/view sharing and to a lessor extent because there are still fewer LC chains than tables and child cursors, so the chains will be longer than zero or one.
Now change the Preset to Custom, (Don't forget to do this or your changes will be undone.) and change the Table/View Share % from 100 to 25, then to 50, then 75, and back to 100. Notice that as sharing increases so is the linking singular intensity. While sharing resources can save memory, the relationship establishment and maintenance dramatically increases (think: CPU consumption and serialization control). Also, the likelihood of a hot spots affecting overall performance increases, whereas when the sharing is minimal, widespread hotspot impact is less likely. Below is the image with Table/View Share % set to 50 and I also zoomed into the image and rotated it until I was satisfied with the image.

The image below I simply zoomed into the center looking over the shoulder of one of the clusters. ...and we wonder why its common to experience LC cache latch or mutex contention?...

The image below shows plotting (set To Plot) only the LC chains with the Visualization set to Points. While the 2D visualization is much more interesting, I'm now trying to convey that the hash chain length is still on average more than one (actually more like 2+) and I'm trying to get all this in a small area, hence the use of the Points visualization.

If you where to click on the Objects or Full To Plot option, the image will be very crowded and pretty much worthless. When you see this happen, it's time to think about a 3D view or reduce the scale. Below is the visualization with the Table/View Share % of 50, a To Plot of Full and the Visualization set to Points. Not real useful but the symmetry is beautiful!

To made the visualization more meaningful, I set the Visualization to 2D, reduced the Scale % to 10 and set the Circle Size to 0.15. This gives me a scaled down version of the LC. Notice that you can see the beginning of the two clusters that were very apparent in the non-scaled 3D visualization. Pretty cool, eh?

I think you get the idea! But what about real production system?
Using the Tool - Production Systems
Now that you are familiar with the tool, the next step everyone wants is to plug their real data into the model! Please remember the tool only shows some of the objects in the library cache and abstractions are made...but still we can learn a lot plus gain a much higher respect for Oracle's shared pool and library cache...not to mention the kernel developers and architects.
Get some real data
The first thing we need to do is extract some key information about the current state of the library cache. As an example, after I dumped the LC as demonstrated above (way above), I then run a simple shell script which parses through the file and summarizes the elements we need. You can download and see this shell script here. Here is an example of what you could see just after an 11g instance recycle.
$ getLCinfo.sh prod18_ora_21939.trc
Library Cache Dump Summary for Oracle 11g
--------------------------------------------
Procs & Funcs : 60
Parent Cursors : 23802
w/ child cursors : 13870
wo/child cursors : 9932
Child Cursors : 23579
per parent (w/csr) : 1.70
Unique Tables & Views : 2970
--------------------------------------------
Enter the data into the tool
The first thing you should do is set the Preset to Custom, then set the Scaling % to 0.01, and finally set the Visualization to Points. A large 3D visualization could takes minutes to render. Do yourself a favor and start with a very scaled down and simple visualization and then start making changes. Now you can carefully enter the numeric values.
The only value we don't have a production value for is the Table/View Share %. Without a more complex gathering script, you'll need to make an educated guess. A good general guess would be around 25%. A large system with only a few tables will approach 100%. A system with thousands and thousands of tables and views will approach 10%. These are simply my best guesses. It's very interesting to increase the shared percentage and see how dramatically the complexity increases!
We also need a value for the number of LC hash chains. You can determine this by looking near the top of the LC dump trace file. If Oracle tries to default the number of LC hash chains to have an average length between zero and one. Even on a very small system, the default number of LC hash can be over 100000. To reduce visualization clutter, I usually set the number of LC hash chains to the sum of child cursors and tables/views. This will ensure the default chain length is one. If this produces too much clutter, just reduce the value while knowing on a real system there are many, many chains with a length of zero. For this example, I entered 17000 LC hash chains.
The image below is the above data carefully entered along with the recommended initial settings. You could have also selected a Preset of Prod 1. It's not too exciting, but our goal is to get something visual and get it quickly. Now we can alter the visually related parameters to get a more useful and better looking visual.
One of the changes I like to make is slowly increase the Scale % and watch the complexity increase. One way to do this is to click on the big "+" sign in the Scale % control box. On my system with this visualization and clicking on the play icon, the visualization essentially locks up Mathematica...so be careful. To get the below images, I repeatedly clicked on the "+" icon and then to decreasing the scale I clicked on the "-" icon. Below is the series of images, each with an increasing scale percentage.
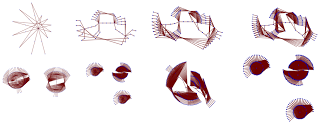
Using The Tool - Myself

For myself, I use the tool mainly while teaching and when working with my customers (that is, my consulting work). I find that creating a visual model of a real system or even a simple example quickly builds a conceptual framework of the LC architecture. Then I can focus on the particular aspect I'm interested in; LC latch/mutex contention, parsing, share pool memory management, hashing, etc.
Using the Tool - Now it's Your Turn
You have access to a powerful library cache visualization tool. Now it's your turn to begin exploring. My recommendation is to first use the provided presets and then customize the control settings. Then gather real production data from your system and begin using the tool to gain insights and increase your communication prowess...after all, like I mentioned at the start of this blog entry, I think what separates Oracle DBAs is their ability to communicate.
Thanks for reading and I hope you find this tool immensely gratifying!
Craig.