Getting laughed at is no fun...
Here's the situation: You run an Oracle Database Statspack or AWR report, determine the key SQL statements, and based on the total elapsed time and the number of executions you determine their average elapsed times. You then tell your user's you can see for their key SQL statement the average elapsed time is X. Then you notice they are kind of snickering because while it does sometimes take this long, it usually doesn't. And in their minds, your reputation and their trust in your skills sinks a little lower. If this situation makes you feel uncomfortable, then read on!
Average elapsed times do not tell us much.
If you have been following my blogs, you may recall that
last February (2011) I blogged about SQL Statement Elapsed Times. One of the key take aways was Oracle Database SQL statement elapsed times are not normally distributed. That is, for a given statement, if you gather a bunch of elapsed time samples, there will not be an equal number of samples below and above the average. Said another way, that nice bell curve histogram most people envision when we say, "The statement takes an average of X seconds to run" is not close to the truth. Not even close.
Since SQL statement elapsed times are not normally distributed, knowing the average elapsed time is not all that useful and can easily mislead people.
Collecting real elapsed times.
To demonstrate this, in the February blog posting I created a procedure to gather elapsed times for a given sql_id and plan_hash_value. The problem was (and still is) the procedure can consume an entire CPU core while collecting data! Perhaps this is OK when gathering experimental data (sometimes), but obviously it's not going to be acceptable when you're performance firefighting on a CPU bottlenecked system and need to get a truer understanding of the elapsed times without hammering your system in the process. But if you'd like, you can download this free tool here.
For months now, I have been planning on creating better SQL elapsed time collector. A tool that ever-so-lightly collects elapsed times for a given statement's sql_id. At the time of this blog entry, a number of DBAs are beta testing and I have some preliminary data from some of them already.
But you may be thinking: What about other methods of gathering elapsed times? There are other methods and below I'll discuss both instrumentation and tracing. And then, I'll compare them with the new tool that's in beta as I type.
What about instrumentation and tracing?
Both instrumentation and tracing can produce very good elapsed time samples. When using instrumentation, the SQL you are interested in must (obviously) be instrumented. Not the module, action, user, or chunk of code, but the actual SQL statement. This is what I'm talking about:
Get time T0
Run SQL statement
Get time T1
Save elapsed time as T1-T0
Tracing is another option that produces solid elapsed times. To prove this to myself, I enabled tracing for a specific sql_id like this:
alter system set events 'sql_trace [sql:5hy19uf6q4unx]';
exec dbms_lock.sleep(60);
alter system set events 'sql_trace off';
I also wrote a bourne shell script trace file processor, which given the sql_id will produce all the sql_id elapsed times contained with the trace file. It was written for Linux based on an Oracle 11.2 trace file, but I suspect can be easily modified if necessary. Click here to view the shell script.
To really prove to myself that these methods worked, I performed an experiment. You can download the master experiment script here. I created a CPU bottleneck (top wait event was latch: cache buffer chain), instrumented the SQL and ran it as I just mentioned above (i.e., get time t0, etc.) while also tracing just that statement. I did the entire experiment twice; each time with a different average sleep time between the executions for the SQL statement I was gathering elapsed times for. The sleep times were log normal distributed, which is much more realistic than a contestant (i.e., uniform) or normally distributed sleep times. Each of the two sample times were around 5 minutes. The experimental setup worked wonderfully.


Figure 1 shows a summary of data collected when the sleep time averaged around 2 seconds and Figure 2 data was collected when the sleep times averaged around 1.8 seconds. The load was also a little more intense during the Figure 2 collection, hence the elapsed times are slightly longer. Within Figure 1 and Figure 2, notice how similar the captured elapsed times are! Statistically speaking, there is no difference between them (alpha=0.05, p-value 0.980) This means both methods will yield the same test results... you pick which one works the best for you!
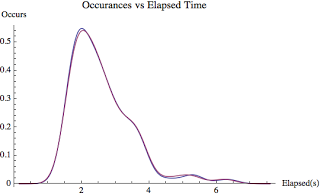
Figure 3 really shows the story! Figure 3 above contains two smoothed histograms based on the data in Figure 2 above. Notice the lines are difficult to distinguish. This means both the instrumentation and SQL tracing elapsed time strategies resulted in nearly the exact same results. And that is what the statistics also told us.
The point of Figure 1, Figure 2, and Figure 3 is both instrumentation and SQL tracing produce good and the same elapsed time data.
That's great if you're application is instrumented or you can (or want to) enable SQL tracing... even at the sql_id level. But perhaps this is not a production system option? Is there another option? Read on...
Another option: The OraPub Elapsed Time Sampler
If you need good SQL statement elapsed times and the SQL of interest is not instrumented and tracing is not a viable option, then consider the OraPub Elapsed Time Sampler. The sampling overhead is minuscule, it is simple to use, it is customizable, and it is amazingly accurate. Here is the link to the tool's web-page. As the web-site states (at this time), if you would like to beta test the tool, please email me at orapub.general@gmail.com. Once the beta testing is completed, the tool will be available on my web-site, but for a few dollars. (update: It's free!)
Little sampling overhead.
All performance tools place some overhead on the systems they are monitoring. I decided to actually observe and honeslty report the overhead. The product incorporates several strategies to reduce the overhead. In the initial beta version there are also three precision options, which impacts the gathering overhead. The precision options are low, normal, and high.
When the product is looking for the specific SQL to complete, the CPU impact is around 1.2%, 1.2% (not a typo) and 20% on a single core for the low, normal, and high precision options respectively. This means if you have a 4 core server and gathering at the low precision the collection server process would be consuming 0.3% of the CPU resources. When the tool is looking for the SQL to monitor, the CPU overhead is 12%, 56%, and 100% on a single CPU core for the low, normal and high precision options respectively. This means if you have a 4 core server and gathering at the low precision, the collection server process would be consuming 3% of the CPU resources (3% of a core = 12% / 4 cores).
I typically use the low precision setting because, as you'll see below, even at this level the results are stunningly accurate. Keep in mind, these numbers are for the initial beta version (3c) and I'm still working to reduce the overhead. I also planning on creating a super-low precision/impact setting.
Simple to use.
First you get the sql_id you want to monitor. (If you found a problem SQL statement in a Statspack or AWR report, the sql_id will be right there in the report.) Then determine the sampling precision and duration. And finally, execute the sampling like this:
exec op_sample_elapsed_v3.sample(600,'5hy19uf6q4unx','low','none','key');
When the sampling is complete, simply query from the sample data table, like this:
SQL> select elapsed_time_s from op_elapsed_samples;
ELAPSED_TIME_S
--------------
1.767666
1.518642
1.518561
...
Simple to install.
You create the sample data table and create a single package. Installation done!
Amazingly accurate.
This is the really cool part! My core objectives where low overhead and to be accurate "enough." As I mentioned above, the overhead is virtually zero. It's easy to collect accurate data when the elapsed times are long, perhaps greater than 20 seconds. But for statements just a second or two long...it becomes very difficult to maintain the balance of low overhead and accuracy.
You can download all the experimental data, some of what I show in this blog entry: NORMAL precision data and analysis ( PDF, Mathematica notebook) and LOW precision data and analysis ( PDF, Mathematica notebook). You can also view/download the my master experiment text file, which is what I copy and paste from when I ran the experiment.
The tool's collected elapsed times are extremely accurate. While I didn't mention this above (would have been a distraction), while gathering the sample data summarized in Figure 1, Figure 2, and Figure 3, I was also gathering elapsed time samples using this tool... I just didn't show that data in those figures. (sneaky, I know) Here is data in both table and histogram format.
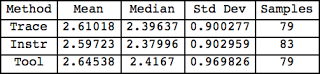
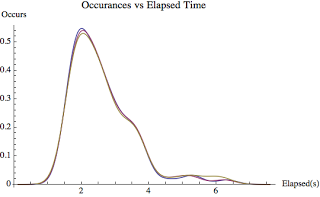
Figure 4 and Figure 5 contains all the data from a 5 minute sample interval at the normal precision level. The sleep time between the SQL statement I was looking for was around 2 seconds (log normal distributed). As you probably inferred by looking at Figure 4 and Figure 5, statistically there is no difference between the elapsed time gathering methods. The smoothed historgram (Figure 5) clearly shows there is virtually no difference in the collection methods.
But what about the low precision setting? After all, the lowest precision setting places a near undectable load on the system. Figure 6 and Figure 7 show the results.
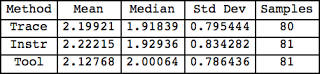
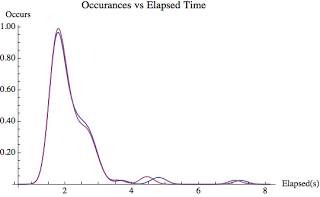
By looking at Figure 4, Figure 5, Figure 6 and Figure 7 you probably inferred that any of the collection methods will work fine and produce the same results (statistically speaking, alpha 0.05). Yes, this is correct!
To summarize the OraPub SQL Elapsed Time Sampler option: If your SQL is not instrumented and SQL tracing is not a production option and you have the spending authority of around a box of candy, then this product should satisfy your requirements. In fact, any of the precision settings will produce accurate results along with a shockingly (or perhaps refreshingly) low sampling overhead.
Again, here's the link to the tool's web page.
Send me your data!
If you would like, you can email me your elapsed time data and I'll run it through a Mathematica notebook, which will crank out a number of graphs and tables. Usually the results are very informative and immensely satisfying.
In Summary...
My objective in this blog entry was not to push my new tool (really). I was just as interested in understanding the accuracy and similarity of all three collection methods (instrumentation, tracing, and OraPub's sampling tool). As I mentioned at the top, its easy to get the SQL statement average elapsed time...but that can be very misleading and not all that helpful. What is needed are good elapsed time samples. This blog entry presents three ways to get really, really good elapsed times with relatively low overhead and at virtually no cost.
Thanks for reading!
Craig.



